
Så kan kommuner ta steg mot länkade data


Denna artikel är en del av en artikelserie om en färdplan för strategisk datahantering i en kommun. Klicka här för att komma tillbaka till huvudartikeln. För att komma till de andra artiklarna i färdplanen klicka på ikonerna i bilden nedan.
Länkade data-teknologi används i stor utsträckning på webben och är det som gör att sökmotorer och sociala medier kan “förutse” vad du är intresserad av och visa dig just det. Det beror på att en oerhört stor mängd kopplingar har lagrats utifrån tidigare användares mönster och när du börjar att söka på något eller interagera med något (t ex att stanna upp i scrollandet) så kan mediet placera in dig på ett mönster och visa dig vad som är nästa stegen i det mönstret. Men vad krävs för att få det att fungera? Och är det här något som är relevant för en kommuns data?
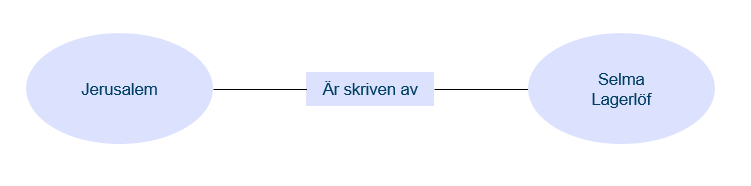
Om vi börjar från början så har all information någon sorts struktur, det är det som gör att vi kan förstå den och tolka den. Det här kallas också semantik. I ett enkelt exempel kan vi tänka oss att vi har en tabell med boktitlar och en tabell med personer som har egenskapen att de är författare. Vi kan då skapa en koppling mellan boktiteln “Jerusalem” och författaren “Selma Lagerlöf”, där kopplingen är “är skriven av”. Om vi hade haft en annan semantik skulle en koppling mellan dessa två värden istället kunna ha betydelsen att en person som heter Selma Lagerlöf bor i staden Jerusalem. Information som behövs för att planera, utveckla och förvalta en kommun är förstås mycket omfattande och komplex, men det är faktiskt möjligt att bryta ned allt till den typen av enkla kopplingar mellan informationsobjekt, vilket också kallas tripplar:
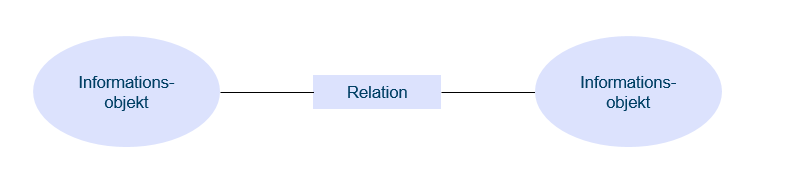
Som i exemplet blir ontologin:
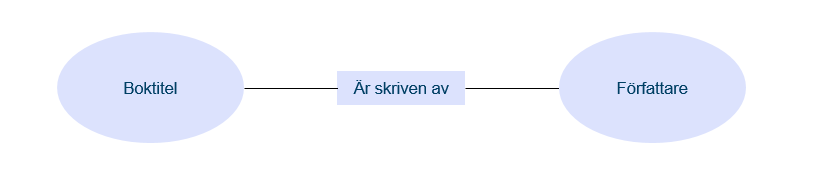
och kunskapsgrafen:
World Wide Web Consortium, W3C, som står bakom utvecklingen av internet, har etablerat en mängd standarder som används mycket brett. En av de grundläggande standarderna heter Resource Description Framework (RDF) och där definieras dessa tripplar (som ofta kallas just RDF-tripplar) tillsammans med unika identifierare, URI:er, som pekar ut var informationsobjektet finns. En URI utgörs ofta av en webblänk. Utifrån den här grunden kan ontologier byggas. En ontologi är en informationsmodell som följer W3C-standarder och därmed kan användas för länkade data. När data läggs in i en ontologi skapas en kunskapsgraf.
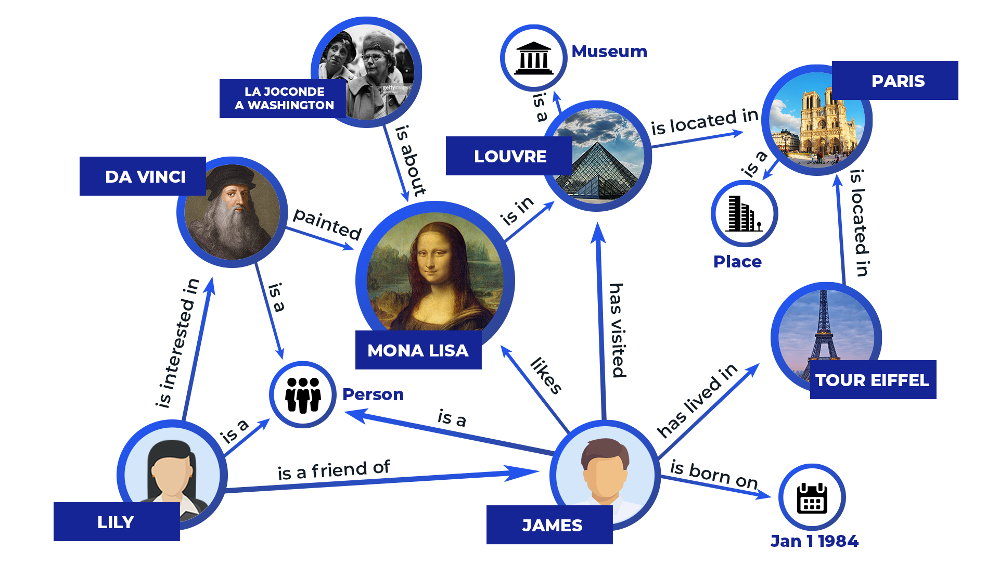
Olika verksamhetsområden behöver sina egna standarder för den information som är viktig just där, men om de uttrycks i form av en ontologi går det att kombinera dem och koppla ihop de olika kunskapsgraferna på ett enklare och mer generellt sätt. En graf kan byggas ut i det oändliga med både terminologi och data eftersom det bara är att koppla på nya noder och länkar. Det här gör att en stor mängd data, från olika håll, kan kopplas ihop och användas tillsammans utifrån nya utmaningar och frågeställningar - just vad en digital tvilling av en kommun vill åstadkomma!
Inom geodata och BIM är länkade data fortfarande ganska omoget även om det pågår mycket arbete både i Sverige och internationellt och det finns ontologier både för IFC och CityGML. Bland svenska myndigheter arbetar Trafikverket målmedvetet med att få vissa av sina datamängder uttryckta som länkade data och många andra har börjat följa. Ett pågående innovationsprojekt inom Smart Built Environment, Interoperabilitet - Digital Samverkan för den byggda miljön, har tagit fram en testbädd i Kista där olika data uttrycks som kunskapsgrafer och kombineras, bland annat anläggningsdata, produktdata, digitala detaljplaner och en 3D-stadsmodell. I projektet tas också ett ramverk för interoperabilitet fram. Information om projektet finns på Interoperabilitet – Digital samverkan för den byggda miljön - Smart Built. Längre fram kommer resultat från projektet att publiceras. På senare år har också stöd för att arbeta med kunskapsgrafer börjat leta sig in i GIS-verktyg som ArcGIS och QGIS. AI-analyser av data från olika källor kommer också att vara enklare om data lagras i en grafstruktur jämfört med andra format som IFC/STEP eller GML.
Så, hur relevant är det här för en kommun och hur tar man sig i så fall an frågan? Om man eftersträvar en digital tvilling som kan användas för många syften och inte bara det den uttryckligen är byggd för att klara är länkade data den teknik som har potential att klara det. Eftersom en kunskapsgraf lätt kan byggas ut vartefter nya behov uppstår stödjer teknologin också ett datacentriskt arbetssätt (att samma data kan användas till många saker) istället för applikationscentriskt arbetssätt (där data är knutet till en specifik verksamhetsapplikation). Det ger också effektivitetsvinster, där data kan ajourhållas vid källan och det inte finns behov av att samla in och förvalta motsvarande datamängd i flera verksamheter i kommunen.
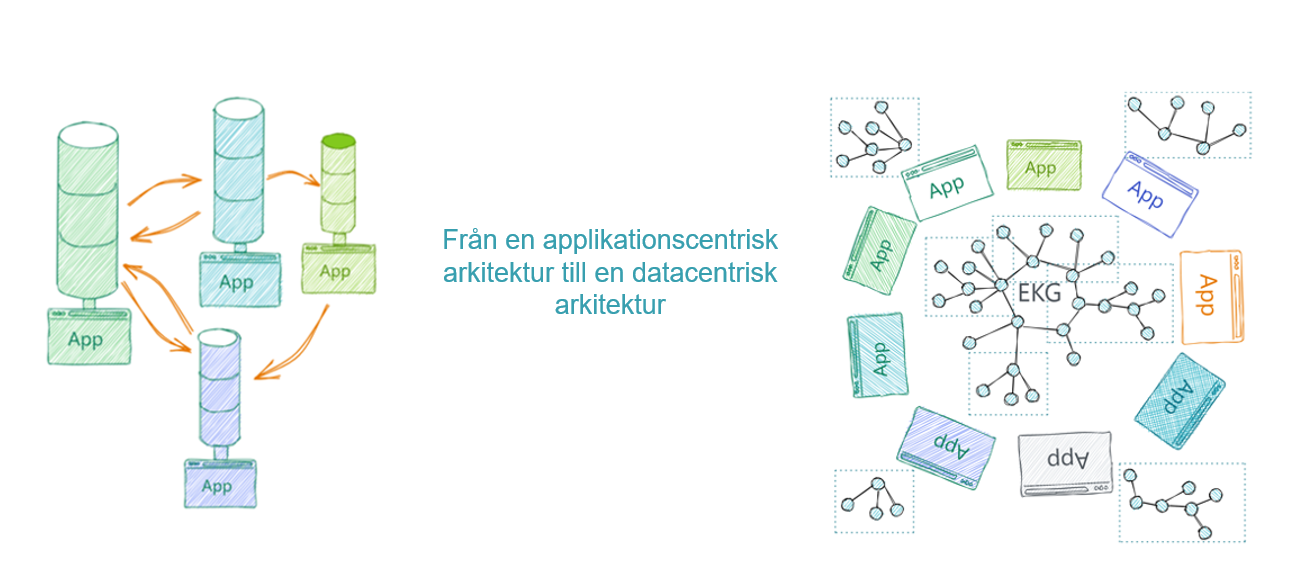
Att uttrycka alla sina datamängder som kunskapsgrafer är kanske inte det första en kommun gör, men lyckligtvis är grunden i stort densamma som för annan informationsförvaltning: ha ordning och reda på data och hur den får delas, använd standarder (ju mer etablerade desto bättre) om det finns och använd unika ID:n. Om en standard används är det stor sannolikhet att andra arbetar med att ta fram och förvalta officiella ontologier för den standarden, se t ex ifcOWL, som är en ontologi för IFC från BuildingSmart. I det fall kommunen använder helt egna informationsmodeller skulle man också behöva definiera en egen ontologi för dem och uppdatera den när ändringar sker i informationsmodellerna, vilket skulle vara ett mycket stort arbete.Det är främst vid utbyte med andra system och processer som kunskapsgrafer ger en ökad interoperabilitet, t ex mellan geodata och BIM. Befintliga och väl fungerande (sub)processer baserade på standarder kan alltså fortsätta på samma sätt som tidigare och måste inte göras om. Då det här är ett område med stark utveckling är en god idé också att följa vad som görs, där projektet Digital Samverkan är en bra ingång.