
Referensarkitektur Digital tvilling (utkast)
Vad kommer digitala tvillingar att ställa för krav på framtidens IT system. I den här artikeln kommer vi att lista ett antal olika funktioner som vi tror kommer att vara viktiga för de framtida IT miljöerna.


OBS den här artikeln är under ett utkast och har publicerats för att du ska kunna ge återkoppling på innehållet så att det blir bättre. Vill du lägga till kommentarer så använd denna länk.
Vad kommer digitala tvillingar att ställa för krav på framtidens IT system. I den här artikeln kommer vi att lista ett antal olika funktioner som vi tror kommer att vara viktiga för de framtida IT miljöerna. Artikeln baserar sig på en rad olika projekt där vi genom åren har fått utveckla olika prototyper inom området.
Men för att kunna diskutera frågan ovan så låt oss börja med att fastställa vad vi tänker på när vi pratar om digitala tvillingar. Om du redan känner att du har koll på det så hoppa ner till senare delar.
Var är en digital tvilling?

Som tidigare nämnt i andra artiklar så sägs ofta digitala tvillingar härstamma från Apollo-projekten där man ofta sparade en fysisk kopia på de rymdfarkoster som man skickade upp på olika uppdrag. Fördelen med att spara dessa var att man kunde utveckla och testa olika lösningar på problem som uppstod innan man över radion skickade upp instruktion till astronauterna. Metoden gjorde det också lättare att samarbeta mellan olika team (tex de som hade ansvar för klimat och luft och värme i farkosten, de som hade hand om styrningen osv). Det gick också lättare att förstå sammanhanget kring den data som kommer in och hur de olika systemen påverkar varandra i farkosten. Vid Apollo 13 uppdraget exploderade dock kapseln och den kopia man hade kvar blev helt plötsligt väldigt olik den som fanns i rymden. I efterhand började man därför att fundera på alternativa lösningar som innefattar matematisk simulering till en högre grad. Ideen plockades senare upp av forskare som jobbade med “product life management” frågor och kom så småningom att börja kallas digitala tvillingar.
En digital tvilling definierats som en virtuell representation av någonting fysiskt men som också har en koppling till det fysiska i form av till exempel sensorer.
Många fastnar i en diskussion kring vad som är en digital tvilling och inte. Viktigt att inse är att Digital tvilling inte är en sak utan en metod som syftar till att sätta samman modeller, data och simuleringar för att skapa förståelse och samarbete. Hur mycket digital tvilling den är i sina olika delar spelar på så vis mindre roll.
Digitala tvillingar och hållbara städer
När det gäller att bygga hållbara och attraktiva städer finns det framförallt två saker som gör att en digital tvilling kan vara till stor hjälp.
- Vi kan sätta samman olika data kring ett objekt eller en stad till en helhet som gör att vi kan gå från data till en detaljerad förståelse för vad som händer och hur saker hänger ihop. Detta kräver att vi kan hantera flera olika datakällor av olika karaktär.
- Det andra som gör att digitala tvillingar kan vara till stor hjälp är att de kan underlätta samarbete mellan olika problemägare. Detta genom att vi kan skapa en gemensam bild av vad vårt mål är samt att vi kan koppla samman och visualisera olika beroenden som olika aktörer har. Om vi tänker oss staden som ett stort kalkylark så kan en aktör fylla i en egenskap i en cell som då direkt påverkar resultatet i andra parters beräkningar som finns i andra celler. Ett område kan ha ett antal invånare som består av summan på invånare i alla hus som finns där. När man bygger nya hus så ökar talet. Elbolaget har en formel som beräknar effektbehovet i området baserat på antal invånare och en annan som visar tillgänglig effekt. När effektbehovet närmar sig tillgänglig effekt kan de inblandade aktörerna varnas.
Några digital tvilling principer
Det finns en rad principer som kan utvinnas ur de projekt vi gjort genom åren samt ovanstående exempel.
Sensordata är i princip oanvändbart utan ett sammanhang
Sensordata är helt intetsägande om man inte skickar med metadata som beskriver vad det är som mäts, vart det mäts osv. Ska man dessutom jämföra det data man får in med annan liknande data som samlats in på andra ställen behöver vi ofta ännu mer information om förutsättningarna. Gäller det energi i en byggnad så vill vi kanske räkna ut energi per kvadratmeter och år eller liknande. Man kan säga att det sammanhang som man ger datat är helt avgörande för om vi ska kunna omsätta datat till information, kunskap och lärdomar.
Problemet avgör modellen
För det första så kan vi säga att grundprincipen för att bygga digitala tvillingar är densamma vare sig det gäller byggnader, städer, fabriker, äldreboenden eller något annat. Det handlar om att dela in världen i lagom stora bitar och sen hitta egenskaper för och beroenden mellan dessa bitar. Hur vi väljer att dela in världen beror till stor del på vilket problem det är som vi behöver lösa.
En digital tvilling är i under ytan en 5-dimensionella realtidskunskapsgraf
För att representera något så krävs det en modell av det fysiska objektet. Ofta men inte alltid är denna modell en 3D modell tex en 3D karta om det gäller en stad. För att kunna beskriva skeenden behöver vi också tiden som en 4:e dimension. I vissa fall finns det fler framtidsscenarios varpå vi också kan prata om 5 dimensionella digitala tvillingar.
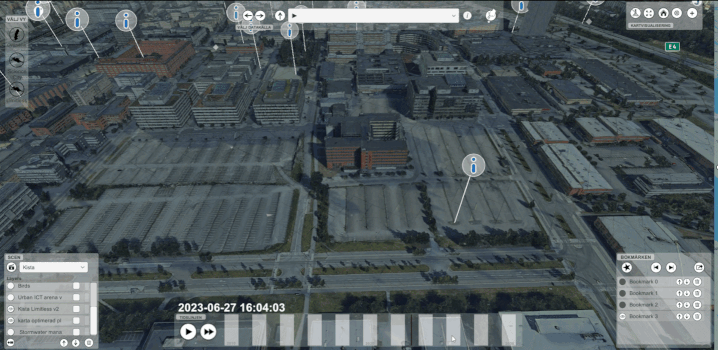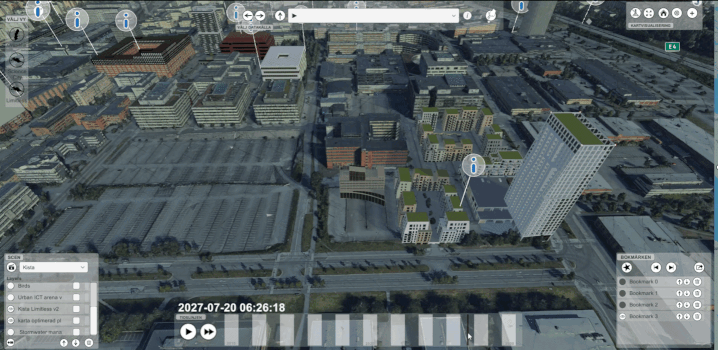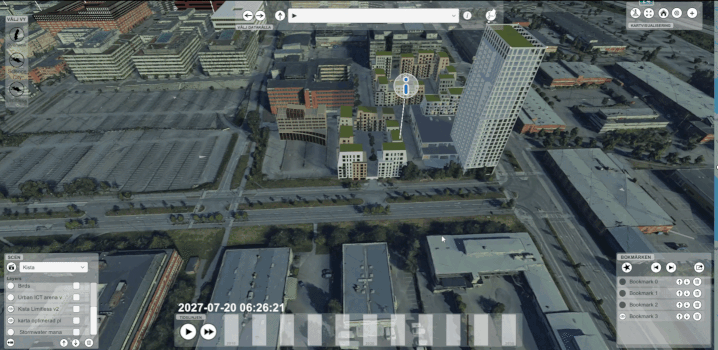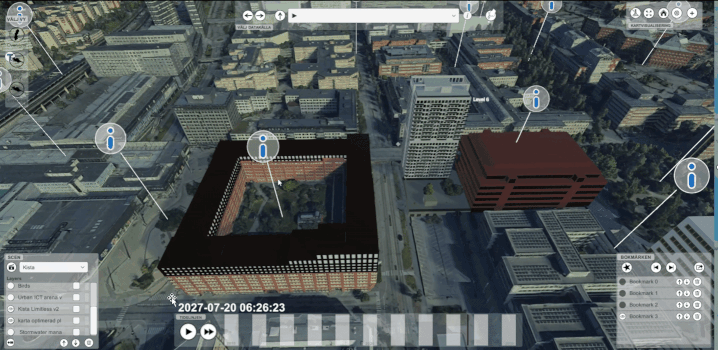
Ur ett dataplattformsperspektiv så behöver vi kunna representera objekt, aktiviteter och andra entiteter med deras egenskaper och deras relationer till andra. Säg att vi har en fastighet så måste vi kunna beskriva olika egenskaper hos fastigheten såsom dess geometri, storlek, antal byggnader på fastigheten osv. Vi behöver också kunna beskriva hur fastigheten är kopplad till andra objekt såsom byggnaderna som finns på fastigheten, det omkringliggande vägnätet, en stadsdel osv. Vi måste också kunna beskriva hur dessa egenskaper och relationer förändras över tid. En egenskap hos ett objekt ska kunna beskrivas som en formel av andra objekt egenskaper såsom i fallet med energianvändningen för ett område. När ett värde ändras så ska alla kopplade egenskaper ändras i realtid. Man kan se det som att hela staden blir som ett stort kalkylark.
LOD måste göras både i tid och rum
När vi zoomar in och ut i en stad så behöver vi också skala detaljrikedomen i datat vi tittar på. En byggandsmodell kanske behöver förenklas när vi ser den på håll jämfört när vi tittar på den nära. En tidserie aggregeras till timmdata eller månadsdata när man tittar på en större tidsperiod. För detta definierar man så kallade LOD (Level of detail) nivåer. Denna skalning behöver göras både över tid och rum.
All data är borde behandlas som realtids data
Ofta vill vi se saker som mera statiska än de är. Men sett över tid är det mesta i förändring. Det finns flera fördelar med att behandla all data som strömmande realtids data även GIS data och meta data för en dataström ifrån en sensor. Detta förenklar dessutom utvecklingen då vi inte kommer att behöva ha separata sätt att komma åt datat. Vi ser idag också att saker som tidigare var statisk data kommer att kunna bli realtidsdata. Ofta byggdes kartor av flygfoton som togs vartannat år i en kommun. En karttekniker satt om översatte informationen i kartan till kartdata. Idag kan vi med en drönare/webkameror och AI skapa sån information i realtid.
En digital tvilling är objekt centrerad snarare än server eller data centrerad
I en digital tvilling utgår vi ifrån objekten, aktiviteterna och andra saker som en verksamhet inrymmer. Om vi tar en lägenhet i ett äldreboende i Haparanda så kommer samma rum att finns beskrivet i ett eller flera system hos kommunen som bedriver verksamheten, ett eller flera system hos Riksbyggen som förvaltar byggnaden och ett eller flera system hos 9solutions som tillhandahåller trygghetslarm, sensorer och talboxar till verksamheten. I en digital tvilling behöver vi beroende på vem som tittar hämta och sammanställa all eller delar av denna data för det aktuella rummet. För det behövs en korslänkning mellan servrar dvs att representationen av rummet på en server tex innehåller en referens för rummets representation på en eller flera andra servrar. Det behövs dessutom möjligheten att använda flera olika sorters data tex bilder eller video strömmar, olika 3D modeller så som geojson-, IFC- eller CityGML- filer som beskriver byggnader och städer, texter i form av mötesprotokoll, rapporter, inköpsordrar osv.
Utmaningar med data inom digitala tvillingar
Det finns flera utmaningar med datat när vi ska bygga digitala tvillingar.
Tillgänglighet
Den ena är att datat är sprid över flera olika organisationer. Inom många kommuner finns datan inte heller tillgänglig så att man kan komma åt den online. Olika förvaltningar inom kommunen jobbar inte sällan så att man kopierar ett data set mellan varandra. Detta gör att de olika kopiorna på data aldrig är i synk. Man måste även lägga tid och resurser på att uppdatera datat med jämna mellanrum. Förädlingen av data av olika förvaltningar blir också lokal och kan sällan nyttjas av andra delar av kommunen. Ett dataobjekt kan också vara inbäddat i en stor fil som som beskriver massor med olika objekt. För att komma åt det behöver vi hantera hela filen trots att det i stunden kanske bara var en enskild egenskap hos ett enskilt objekt som intresserade oss.
Federerad data
Att centralisera data i en enda stor plattform för en stad ses inte heller som en väg framåt då en sådan plattform skulle behöva hantera enorma mängder data och dessutom göra systemet sårbart. Inom olika initiativ inom EU tänker man sig så kallade "data spaces" en rymd där man kan komma åt data hos de olika dataleverantörerna men där varje leverantör behåller datat i sina system. För att detta ska fungera smidigt så krävs det någon from av broker-funktion som gör det möjligt för oss att koordinera inloggning till en massa olika aktörers system man även att kunna hitta vart det finns data.
Saknade dimensioner i datat
Inom vissa områden har man inte haft som tradition att spara ner en historik. Stockholmstad sparar som exempel inte ner sina kartdatalager så att man på ett enkelt sätt kan gå tillbaka i tiden för att se hur staden såg ut då. Men sensor data sparar vi däremot ofta ner en historik. Detta gör att om jag ska visualisera tex luftkvaliteten i en korsning så vet jag inte ens om korsningen fanns där när jag går bakåt i tiden. De filformat som används saknar också ofta stöd för tidsstämplar vilket gör att om man sparar ner historisk data så gör man inte det när objekten ändrades utan tar snarare en periodisk kopia på hela databasen eller filen. Traditionell GIS data sakar också ofta höjdinformation. En vägmodell som finns i 2D och som ska visualiseras i en 3D karta behöver därför konverteras för att inte hamna under marken.
Semantisk data koppling saknar idag och är dyrt att framställa
Byggandet av kunskapsgrafer är viktigt både för att vi ska kunna sätta data som vi får in i ett sammanhang men också för att koppla ihop simuleringar så att vi förstår hur en händelse eller förändring i ett system påverkar andra system. Ofta kan man koppla ihop saker geografiskt dvs vi kan härleda att att att en viss byggnad hör till en viss fastighet genom att den befinner sin inom en fastighets markområde och att fastigheten hör till en viss stadsdel genom att den befinner sig inom det geografiska området. Ibland finns det även dataset som redan har kopplingar genom att tex fastighetens id sparats ner som en egenskap på en byggnad. I många fall så är det dock svårt att göra kopplingar och identifiera nya objekt med automatik. AI algoritmer kan tex hitta alla fönster i en 3D modeller men det blir lätt sammanblandningar mellan tex solceller och takfönster. I bland har vi olika datakällor som tex en video ström och BIM data där vi kanske kan se ett bord i båda men där vi måste göra kopplingen att båda borden är samma bord.
En referensarkitektur för digitala tvillingar
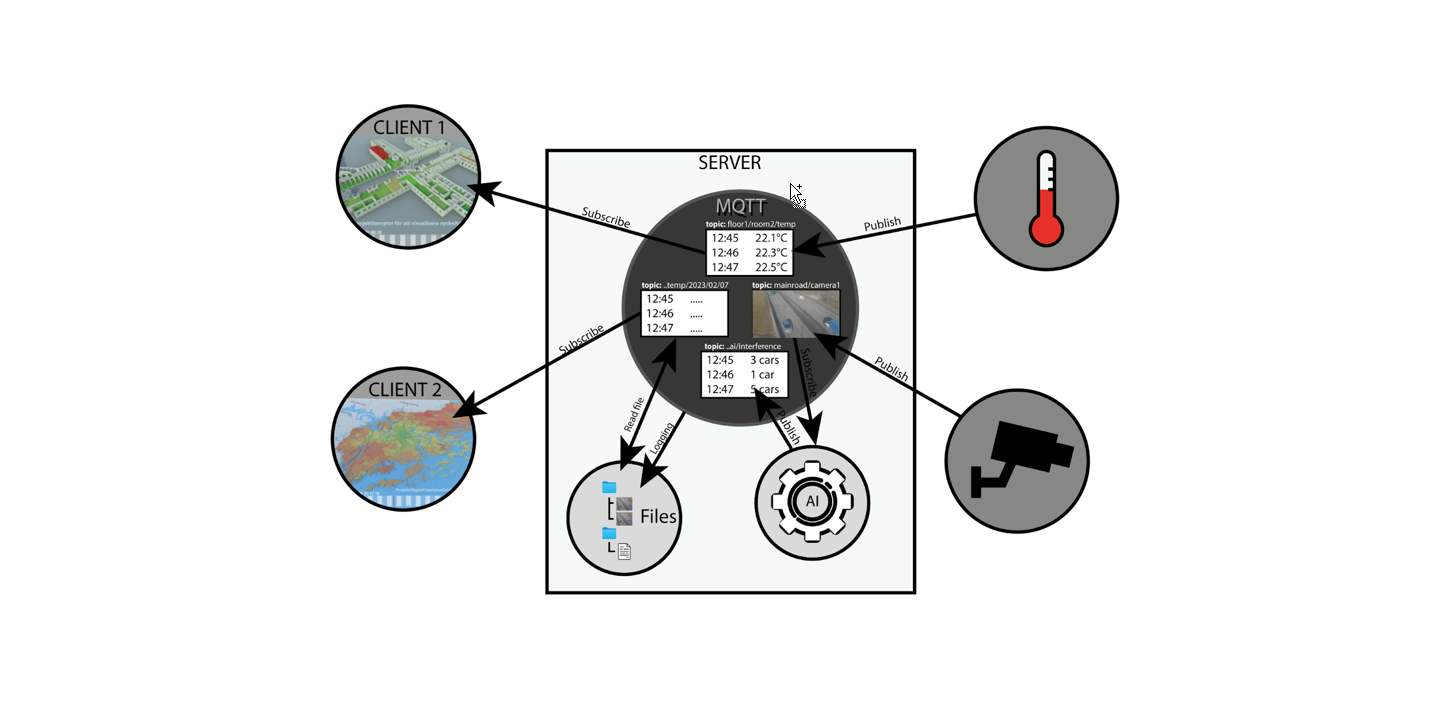
I projektet Digital Vision kista har vi byggt upp en testplattform för att kunna hantera datat till vår digital tvilling. Det finns flera olika EU iniativ som tittar på olika verktygslådor (eng. Toolkit) för så kallade lokala digitala tvillingar. Några av dessa förväntas bli tillgängliga någon gång kring 2027. Men i väntan på dessa så har vi byggt en egen lösning för att utforska hur vi kan åstadkomma en digital tvilling plattform.
Vår lösning baserad på MQTT vilken kan sägas vara ett slags chattrum för sensorer med syfte att frånkoppla data producenter från data konsumenter. En sensor publiserar ett meddelande i ett chattrum och alla som är intresserade av datat kan om de har behörighet ansluta sig till chatrummet och lyssna på meddelandena.
Denna model att kommunicera data kallas för publish/subscribe och skiljer sig från tex REST API:er på så sätt att i att man ligger uppkopplad mot servern hela tiden och får data skickat till sig när någon av de ämnen (topics) som man prenumererar på ändras. Genom att använda publish/subscribe möjliggör vi realtids applikationer så som chattkommunikation mellan olika organisationer, realtidsuppdaterade nyckeltal, larm osv.
En gemensam adressrymd och länkningar
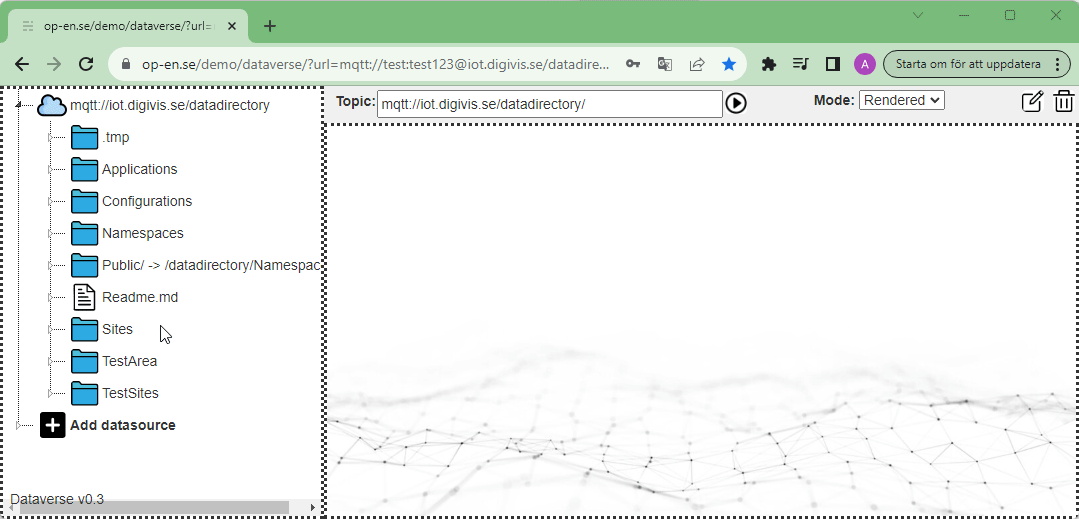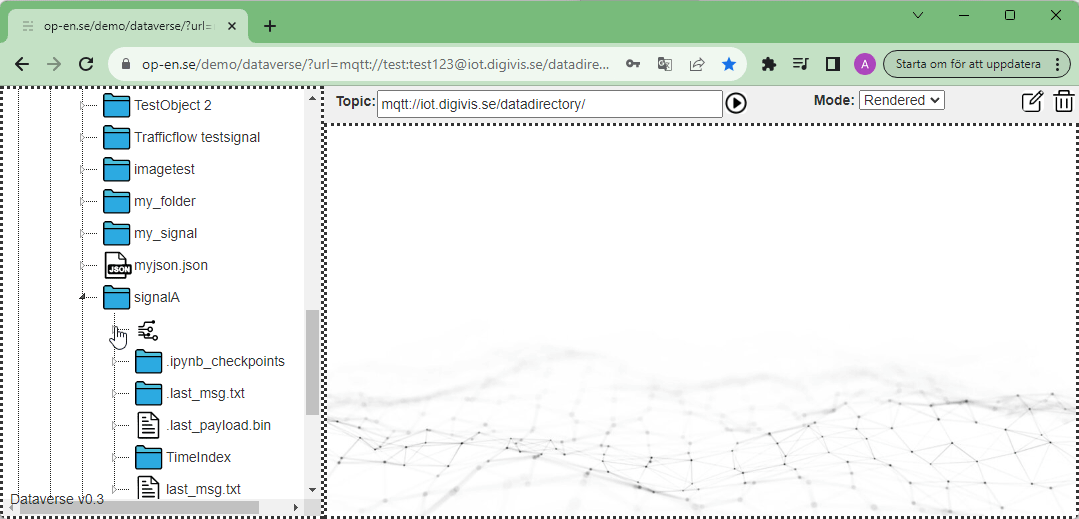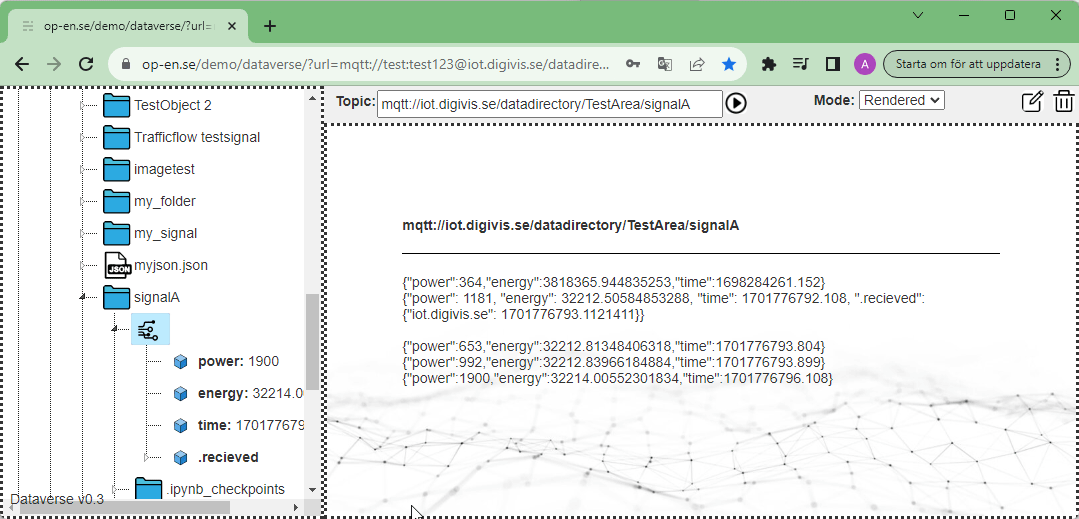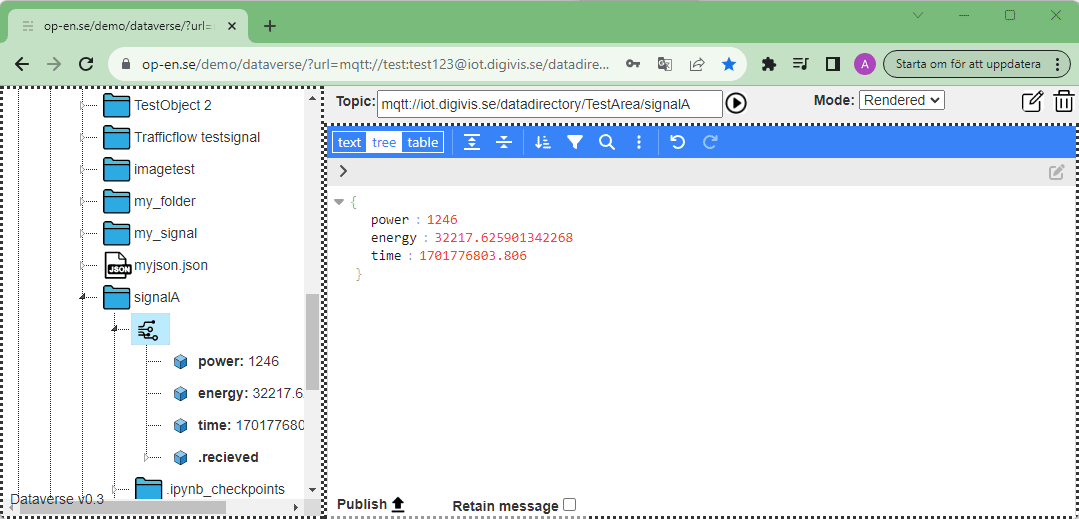
Normalt så pratar man om topics när man jobbar med MQTT ett topic är ofta uppbyggt i formen: antons_hus/vardagsrummet/stereo/elförbrukning eller som i exempelt ovan: datadirectory/TestArea/signalA. I digital vision Kista skapade vi kompletta URL:er som göra att man kan adressera flera serverar och flera olika data resurser. I ett projekt med ett äldreboendet besrkrivet ovan så kanske vi hittar viss information om lägenhet 1014 på kommunens server och viss data på fastighetsförvaltarens server.
På kommunen så kanske vi hittar information om rummet på:
mqtt://iot.haparanda.se/datadirectory/operation/hemstranden/floor_1/appartment_1014
Medan hos fastighetsförvaltaren på:
mqtt://iot.riksbyggen.se/datadirectory/realestates/Lunden_16/appartment_1014
Hos kommunen så kanske det finns egenskaper så som:
.../appartment_1014/resident
.../appartment_1014/contact
som innehåller information om den boende samt info om kontaktpersonen för den aktuella lägenheten.
Hos fasighetsförvaltaren kanske vi hittar egenskaper så som:
.../appartment_1014/geometry
.../appartment_1014/area
.../appartment_1014/inspection date
som beskriver lägenhetens utformning, storlek och när den senast var inspektera.
För att en digital tvilling ska kunna kombinera alla dessa egenskaper i en vy så behöver vi också en egenskap hos båda dessa som heter.
.../appartment_1014/@
Denna egen egenskap innehåller länkar till vart vi kan hinna datat kring det aktuella objektet på andra serverar.
{ "Riksbyggen": "mqtt://iot.riksbyggen.se/datadirectory/realestates/Lunden_16/appartment_1014" ,
"Haparanda kommun": "mqtt://iot.haparanda.se/datadirectory/operation/hemstranden/floor_1/appartment_1014" }
Individuellt adresserbara egenskaper
Om vi lägger in en geojson fil som tex innehåller stadsdelar i Stockholm kommer vår testmiljö att exstrahera innehållet i denna och göra de enskilda detaljerna individuellt adresserabara.
Om filen ligger på:
mqtt://iot.digivis.se/datadirectory/providers/dataportalen.stockholm.se/stadsdelar/stadsdelar.geojson
kommer vi att kunna läsa ut data om tex Kista på:
mqtt://iot.digivis.se/datadirectory/providers/dataportalen.stockholm.se/stadsdelar/stadsdelar.geojson/kista
en enskild egenskap så som ytan kan vi då tex hitta på:
mqtt://iot.digivis.se/datadirectory/providers/dataportalen.stockholm.se/stadsdelar/stadsdelar.geojson/kista/area
Historisk data
Normalt så används inte system som MQTT för att leverera historisk data. Vi ville dock ha ett enhetligt sätt att få all data. Lösningen blev att vi skapade ytterligare ämnen eller chatrum som innehöll en sensors historiska data.
Vill vi veta vad arean för Kista var 1 april 2022 så premierar vi på ämnet:
mqtt://iot.digivis.se/datadirectory/providers/dataportalen.stockholm.se/stadsdelar/stadsdelar.geojson/kista/area/TimeIndex/2022/04/01
Länk till presentation på ämnet