
Referensarkitektur för digitala tvillingar



I projektet Digital vision Kista – Stockholms väg till en digital tvilling fick vi, genom en prototypdriven ansats, möjlighet att undersöka hur en digital tvilling bäst kan byggas – både på klient- och serversidan. I denna artikel presenterar vi centrala resultat från arbetet och diskuterar hur ett system kan utformas för att underlätta datadrivet samarbete och koppla samman heterogena datakällor och skapa system som kan ge rätt personer rätt information vid rätt tidspunkt.
Artikeln blev till slut ganska omfattande. Inledningsvis beskriver vi bakgrunden till våra designkriterier och varför vi menar att staden behöver en distribuerad femdimensionell realtids-kunskapsgraf för att underlätta samarbete. I den andra delen går vi igenom hur vår prototyp fungerar, med chattrum där befintliga datakällor mappas in. Ambitionen har varit att förklara allt på ett sätt som även personer utan teknisk bakgrund kan följa. Om vi har lyckats återstår att se — lämna gärna kommentarer eller frågor i kommentarsfältet längst ner.
Att bygga en digital tvilling handlar i grunden om att koppla samman data till en meningsfull helhet och möjliggöra så kallade obrutna dataflöden där data - om det är önskvärt - i realtid kan gå från sensor, till beräkning och slutligen användaren. När detta lyckas kan vi skapa en synkroniserad förståelse för hur olika delar av staden hänger ihop och påverkar varandra, och motverka det tunnelseende eller åtskilda lägesbilder som ofta uppstår i eller mellan organisationer och förvaltningar. Ett sådant tunnelseende beror i stor utsträckning på begränsningar i möjligheten att se bortom den egna verksamhetens perspektiv, men kan också vara kopplade till just osynkade datamängder. Vi kommer lite senare att beskriva projektets vision med att rätt person dynamiskt ska få rätt information vid rätt tidpunkt.
För att förstå hur data kan kopplas samman på ett mer effektivt sätt studerar vi dels hur kommuner idag arbetar för att göra data sökbar och tillgänglig mellan organisationer, dels hur denna data faktiskt kombineras och används. Genom detta arbete kan vi identifiera återkommande hinder och utmaningar, och utifrån dessa ta fram en referensarkitektur som bättre stödjer datadrivet samarbete än dagens arbetssätt.
Arbetet tar avstamp i ett antal återkommande utmaningar som identifierades genom möten och intervjuer med aktörer från olika delar av staden under projektets gång. Problembeskrivningarna visar att dagens arbetssätt ofta präglas av manuella kopplingar, fragmenterad information och isolerade system. Detta försvårar helhetsperspektiv, leder till dubbelarbete och ökar risken för felaktiga eller suboptimala beslut.
Exempel på problembeskrivningar
Här följer ett axplock av de problembeskrivningar som användes i projektet som inspiration till den målbild och referensarkitektur som arbetet utgår från. Syftet är att illustrera de typer av problem och utmaningar som arkitekturen är tänkt att adressera.
1. Sammankopplingar av data är tidsödande men återanvänds sällan.

Nästan alla utredningar och beslut som tas i en kommun idag handlar om att koppla ihop data ifrån olika datakällor. Som ett exempel kan vi ta handläggningen av ett bygglov. Här sitter en person med ett dokument som handlar om vad någon vill göra på ett visst ställe (bygglovsansökan), ett annat dokument som handlar om vad man får göra på det aktuella stället (detaljplanen) och så ett dokument som beskriver vad som gäller bygglov generellt. Personer kopplar sedan ihop olika bitar av information i dessa dokument i sitt huvud och skriver ner beslutet i ett nytt dokument. Om vi skulle kunna skapa och spara dessa kopplingar digitalt så skulle mycket vara vunnet både för att underlätta för handläggare och utredare men även för framtida processer där kopplingarna skulle kunna återanvändas.
2. Många aktörer vet inte vilken data som finns

Många aktörer är inte medvetna om vilken information och vilka data som redan finns tillgängliga. Vid möten mellan exempelvis byggaktörer och staden hörde vi gång på gång samma behov formuleras: ”Vi skulle behöva data kring …” — varpå svaret ofta var: ”Den datan finns redan.”. Stockholm stad har kommit ganska långt med sin plattform dataportalen.stockholm.se där man kan söka efter existerande data men trots det är det svårt för olika organisationer att hitta data som de skulle gagnas av att ha tillgång till.
EU har etablerat olika inisiativ inom området som dataportalen data.europa.eu för att göra offentlig information från EU och medlemsländer mer tillgänglig. Portalen fungerar som en gemensam katalog där stora mängder dataset samlas via standardiserad metadata. Men det finns fortfarande begränsningar i hur öppna data kan sökas. De flesta dataportaler – både på EU-nivå och nationellt – indexerar främst metadata om dataset, inte själva innehållet.
Tre datanivåer
- Dataset – ett datapaket, exempelvis “Trafikmätningar i Stockholm”.
- Metadata – beskrivningen av datasetet (titel, nyckelord, ansvarig aktör).
- Objekt och egenskaper – det faktiska innehållet i datan, exempelvis en plats som Kista, en byggnad eller en mätpunkt och deras attribut.
Om man exempelvis söker på Kista i Stockholms dataportal får man inga träffar, trots att Kista förekommer i flera dataset. Det beror på att sökningen sker i metadata, inte i objektens innehåll. Objektet finns alltså i datan, men är inte sökbart på portalen. Vi har därför en bit kvar innan öppna dataset blir fullt sökbara på objekt- och egenskapsnivå.
3. Avdelningar inom staden kopierar data mellan varandra manuellt

Olika avdelningar inom staden kopierar ofta viktig data mellan varandra. I bästa fall cirka en gång om året. Detta gör att man aldrig är i synk riktigt eller har samma data. Nya dataset tas fram på data som redan är föråldrad och lever därefter kvar länge. Inom en svensk kommun ville man veta hur mycket en viss ritning och hittade då 31 olika kopior av den på olika system.
4. Svårt att ha koll på allt som händer omkring oss

Som aktör i ett område är det svårt att hålla koll på allt som händer omkring en eller förstå konsekvenserna av olika planer man har själv för omgivningen. När olika aktörer möts så ser vi ofta hur ett informations byte startar i en dialog. Man bygger långsamt upp en delat förståelse. Men inte all viktig information kommer med vid möten som denna och samma stund som de lämnar mötet så börjar den delade förståelsen att luckras upp igen.
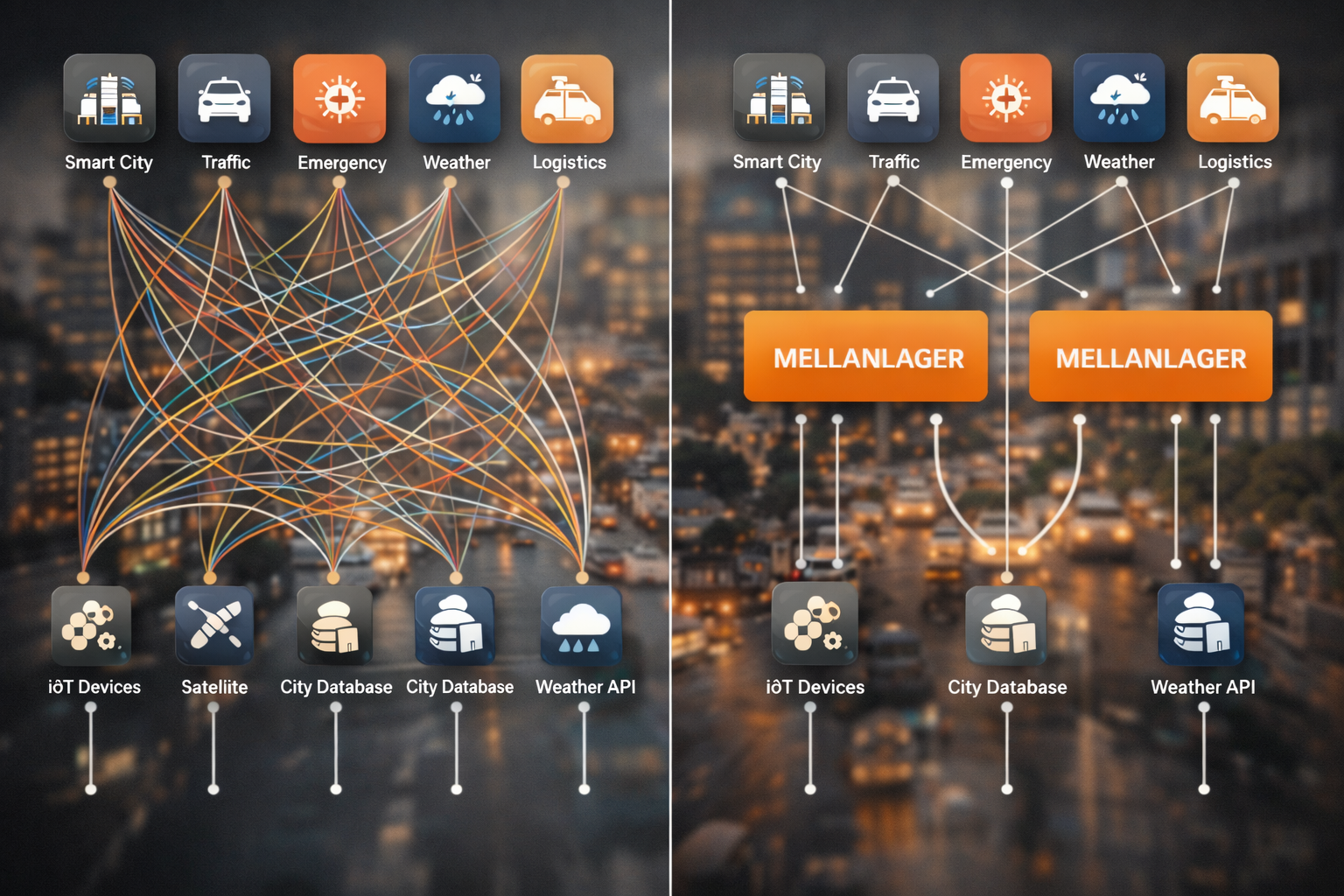
5. Punkt till punkt integration är ohållbart
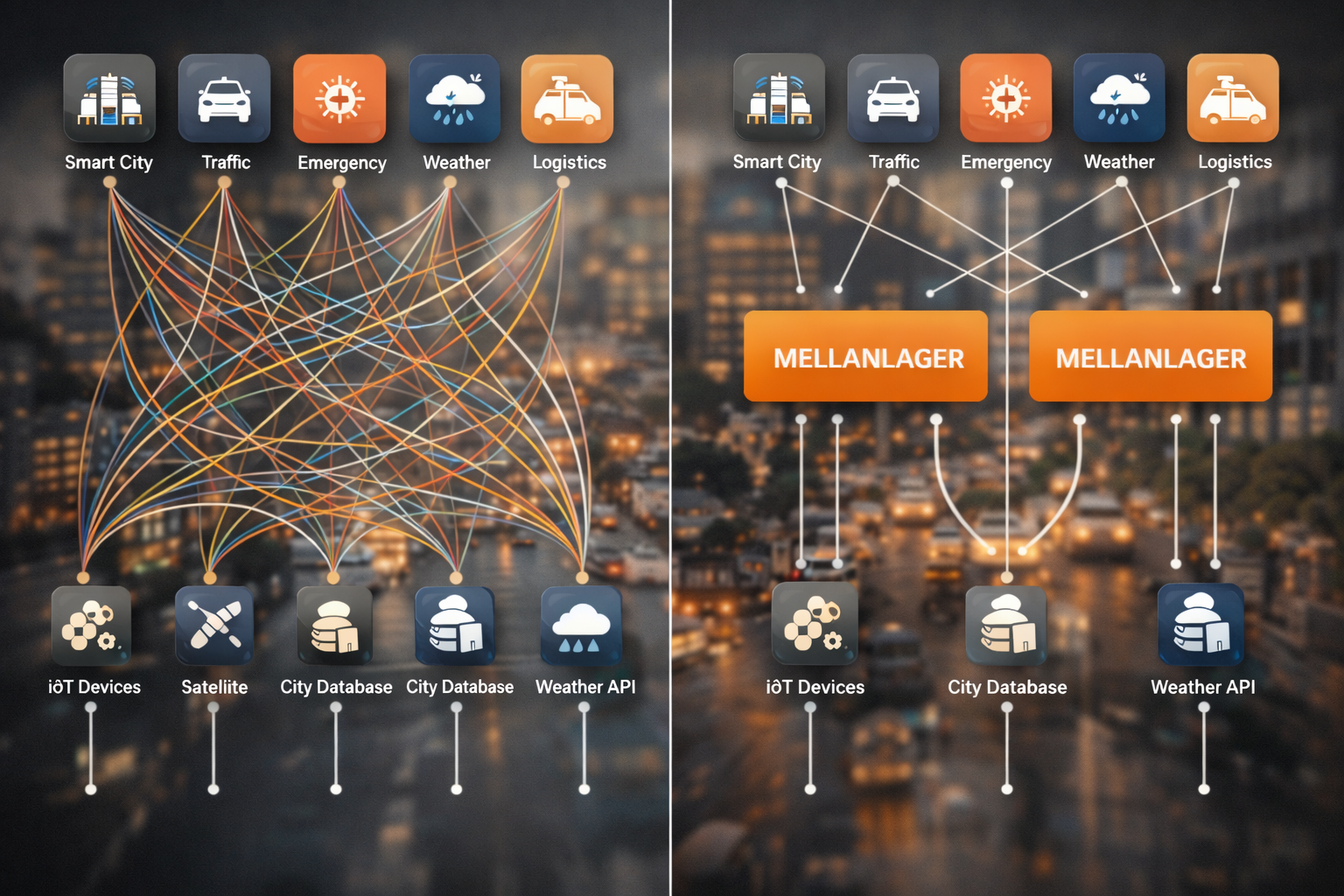
För att möjliggöra ett helhetsperspektiv behöver de applikationer som stödjer beslutsfattande i en stad kunna integrera ett stort antal datamängder från många olika system. Om detta görs genom punkt-till-punkt-integrationer blir lösningen snabbt komplex, kostsam och svår att förvalta över tid. Det finns därför ett behov av ett mellanlager som abstraherar bort systemgränser och förenklar åtkomst till data. Inom EU pratas det om tex om dataspaces där vi kan integrera system genom att exponera dem till en gemensam data rymd med så kallade data connectors och federerade inloggningssystem. Vi måste dock gå ännu längre än så för att kunna bygga digitala tvillingar. För att fullt koppla ihop olika utredningar från olika system så måste de enskilda objekten och egenskaperna i våra dataset vara fullt adresserbara. Först då har vi en fullständig integration mellan system.
6. Data kommer förbli distribuerad

Vi kan aldrig räkna med att alla data ligger på en server i en stad. Detta då det rör sig om för stora volymer, de som äger datan ofta vill behålla kontrollen över den osv. För att skapa en helhet behöver vi kunna koppla samman data som finns på olika servrar på objekt och egenskaps nivå.
7. Samma objekt finns beskrivet flera gånger utan koppling

Ofta finns ett objekt beskrivna flera gånger i olika system. Säg en vägtunnel tex. Den kan finns definierad både i en dagvattensimulering, en traffiksimulering och omnämn i någon form av medborgarrapportering. Genom att länka samman dessa objekt kan varje enskild utredare får en bredare förståelse av sin del i helheten under utredningsarbetet. Kommuner lägger idag också mycket tid på att lägga samman olika utredningar denna tid kan då också kraftigt minskas.
8. Historisk data tas ofta bort inom GIS

När staden uppdaterar sina kart datalager så skriver man ofta över eller lägger till data. En gång om året så skickas en pdf till stadsarkivet på vissa grund kartlager men det är ofta svårt att gå tillbaka i tiden och förstå exakt hur det såg ut vid ett tillfälle. Om vi tex har en luftkvalitetsmätare som visar höga värden vill vi ju tex gärna veta om det pågick vägarbeten eller om ens vägen fanns i anslutning till den när vi har de höga värdarna.
Vägen till bättre samarbete -länkad realtidsdata
De ovan beskrivna problemen illustrerar behovet att att kunna hitta data, att kunna sammanlänka den digitalt så att länkningarna kan återanvändas och att dela data utan att kopiera den utan att istället behålla en levande koppling till grunddatasetten. En viktig del av förståelsen är att all data är föränderlig även de data som väldigt sällan ändras och som kan förefalla statisk. För att vi ska kunna samarbeta behöver vi betrakta all data som realtidsdata. Dvs information som när som helst kan bli justerad, korrigerad eller uppdaterad.
Projektets vision - Rätt information till rätt person vid rätt tidpunkt
Context awareness är ett centralt begrepp inom HCI som skapar grunden för situerat och relevant beslutsstöd. Genom att förstå användarens situation försöker vi anpassa informationen så att användaren får rätt information vid rätt tidpunkt. Den tekniska grunder för oss att kunna göra det är att vi förstår hur olika objekt i våra modeller hänger ihop. Detta kan vi göra med en så kallad kunskapsgraf. Med denna graf så ser vi vilka objekt som är kopplade till andra objekt och vilken relation de har.
En av visionerna som utvecklats för arbetspaket är att vi baserat på ett antal händelse och en kunskapsgraf ska kunna skapa en skräddarsydd tidslinje för tex en fastighetsförvaltare i Kista där denne kan se var som påverkar verksamheten framöver. Alternativt att någon som planerar att bygga nytt i ett område kan bli lotsade till relevanta dataset tex situationen kring dagvatten eller trafik och tidigare utredningar.
Att slå samman och länka data
För att vi i den digitala tvillingen ska kunna skapa en helhet så måste vi slå ihop data med olika dimensioner och geografiska indelningar från många olika datakällor.
Datats geografiska indelningar
I projektet arbetade vi med flera olika datatyper kopplade till skilda geografiska indelningar. Dessa kan övergripande delas in i två huvudkategorier: semantisk data (objektbaserad) och rasterdata (grid-, rut- eller pixelbaserad).
För semantisk data bestäms den geografiska indelningen av objektens faktiska utsträckning, exempelvis byggnader, vägar eller fastigheter. Rasterdata utgår i stället från en i förväg definierad, matematisk indelning av ytan. Ett typiskt exempel är väderprognoser, där data alltid rapporteras enligt ett fast rutnät, oberoende av underliggande objekt. Ett annat exempel är bilddata från sensorer, såsom flygfoton, där rutindelningen motsvarar kamerans pixlar. I dessa fall är rutornas placering kopplad till hur och var sensorn befann sig vid insamlingstillfället.
För rasterdata innebär detta att rutnätet inte nödvändigtvis är konstant över tid, utan i stället är knutet till det specifika datasetet.

När data ska kopplas mellan olika objekt och rutnät uppstår ofta imperfekta överlapp. Ett semantiskt objekt, exempelvis en byggnad, kan ligga inom flera prognosrutor samtidigt. Detta innebär att värden måste aggregeras, till exempel genom medelvärden eller spann.
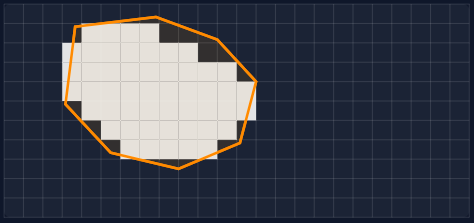
Om vi tar ett exempel där vi har ett rutnät av förutsägelser för hur mycket temperaturen kommer att ha ökat om 5 år och en fastighetsgräns kan vi tex ta medelvärdet av de rutor som faller inom fastighetsgränsen (vita rutor i bilden oven) och ge fastighetsobjektet en ny egenskap i forma av ökad temperatur om 5 år. Med just SMHI väderprognos rutor så är ofta rutorna 2,5 x 2,5 km stora. Ett objekt som en fastighet är då ofta helt inom rutan men kan i vissa fall ligga precis på kanten mellan 2-4 rutor. För satellit och ortofoto så kommer rutorna att vara olika för varje ny bild som vi får eftersom kameran aldrig kommer att vara på exakt samma ställe när bilderna tas.
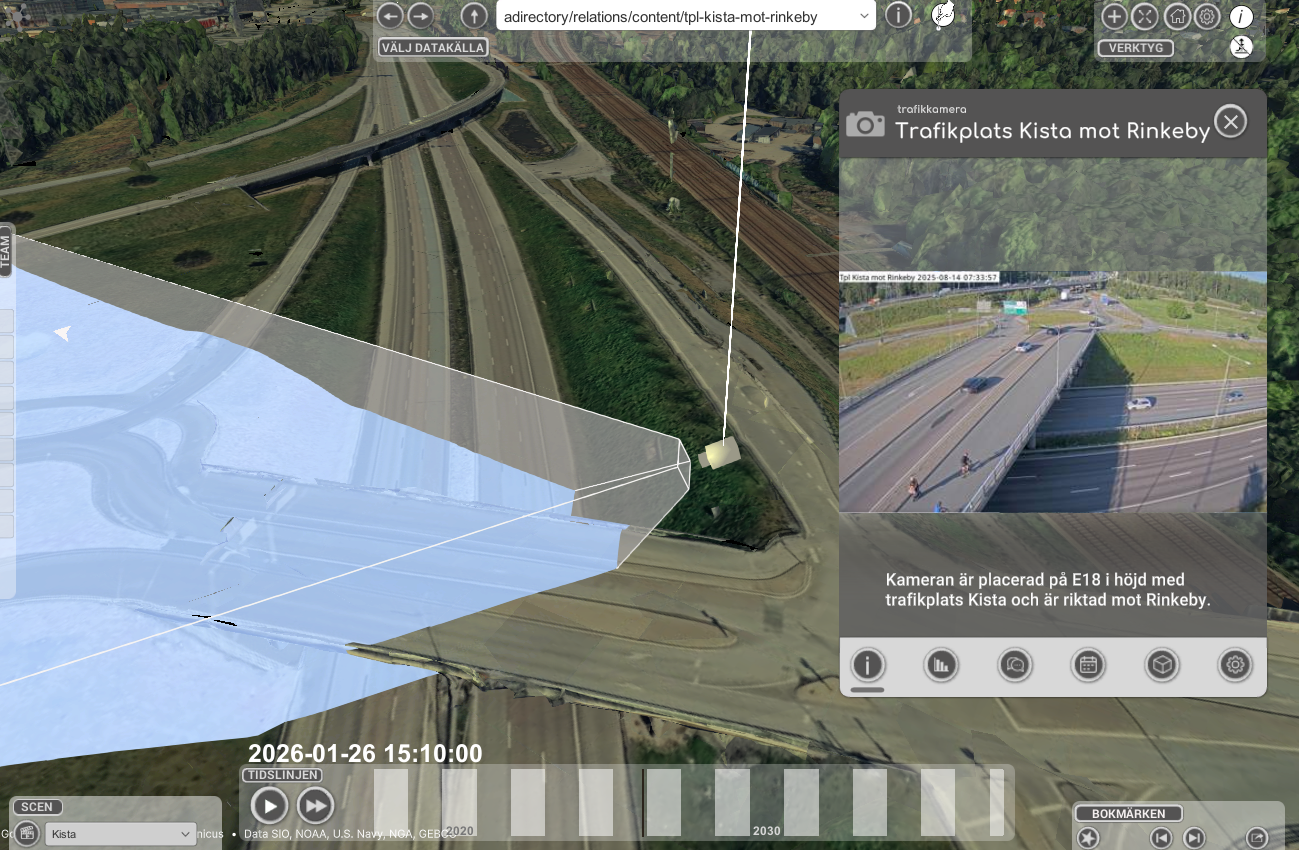
I projektet tittade vi också mycket på kamerabilder från tex trafikkameror eller kameror som vi satte upp över Ericssons parkeringar. I dessa fall så kommer kameras avkänningsområde att definieras som en så kallat frustum. Dvs en rektangel som växer med avståndet till kameran. Varje pixel i kameran kommer att falla på ett eller flera semantiska objekt så som vägar, hus, bilar, fastigheter osv. Om vi tex gör AI analys av bilden för att räkna bilar behöver vi sedan räkna om bildens koordinater till 3D modellens för att tex förstå vilken av filerna och i vilken riktning som bilen åker.
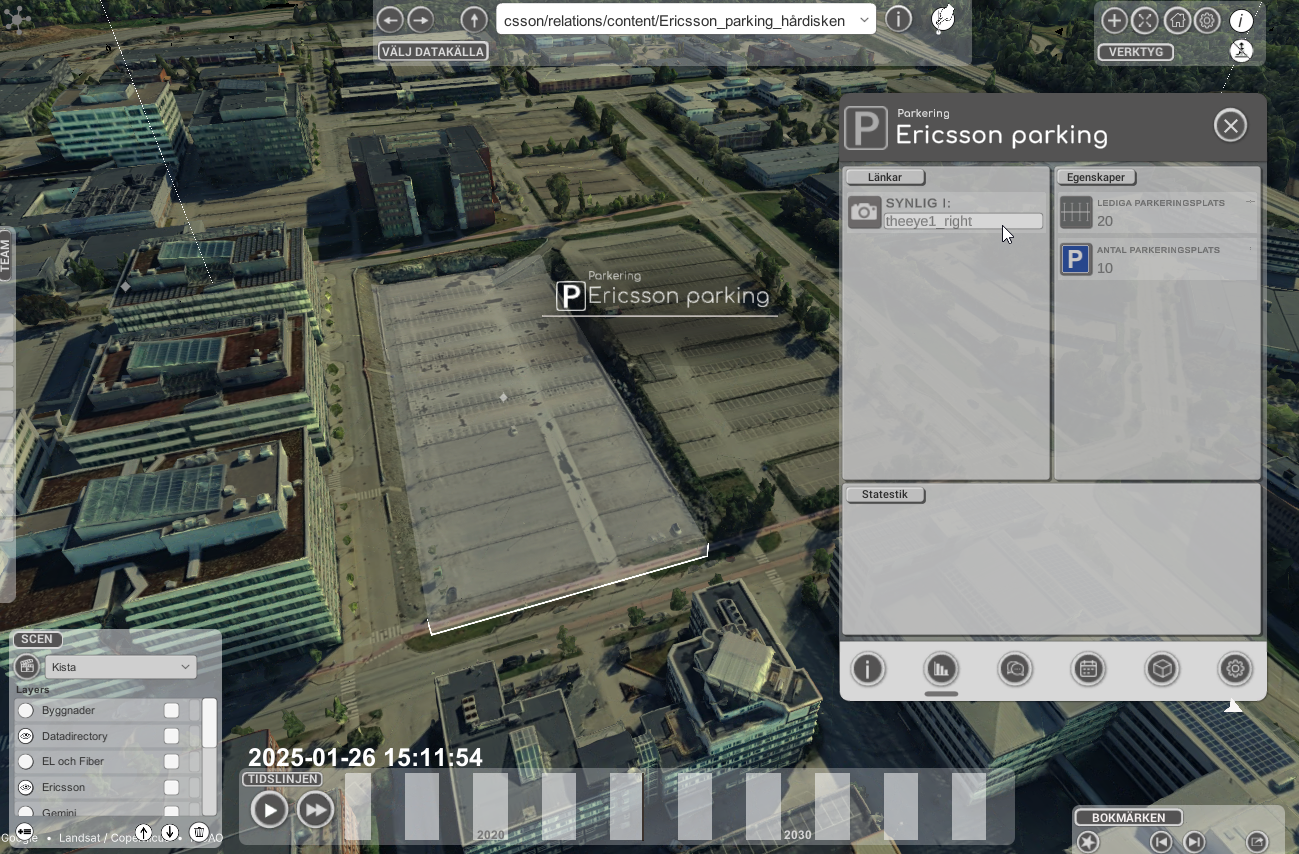
Som en del av läkningen av objekt så behöver vi också veta vilka kameror som ett visst objekt är sydliga i. I bilden har vi klickat på objektet Ericssons parkering i Kista och ser att den finns i kameran "theeye1_right" uppe i Kista science tower. Vi kan vidare även koppla exakt vilken parkering som motsvarar vilka pixlar i bilden som motsvara vilken parkerings ficka och på så sätt se vilken av parkeringarna som är ledig respektive upptagen.

Datats dimensioner
En annan sak att som man behöver förstå när man ska lägga samman data är vilka dimensioner som finns i de olika datasatsen.
I data beskriver dimensioner vilka frågor man kan ställa om ett värde. Varje dimension svarar på i vilket sammanhang ett datapunkt gäller.
Exempel:
- Var? → rumsliga dimensioner
- När? → tidsdimension
- I vilket alternativ? → scenario
Ett värde utan dimensioner saknar kontext och är svårt att tolka.
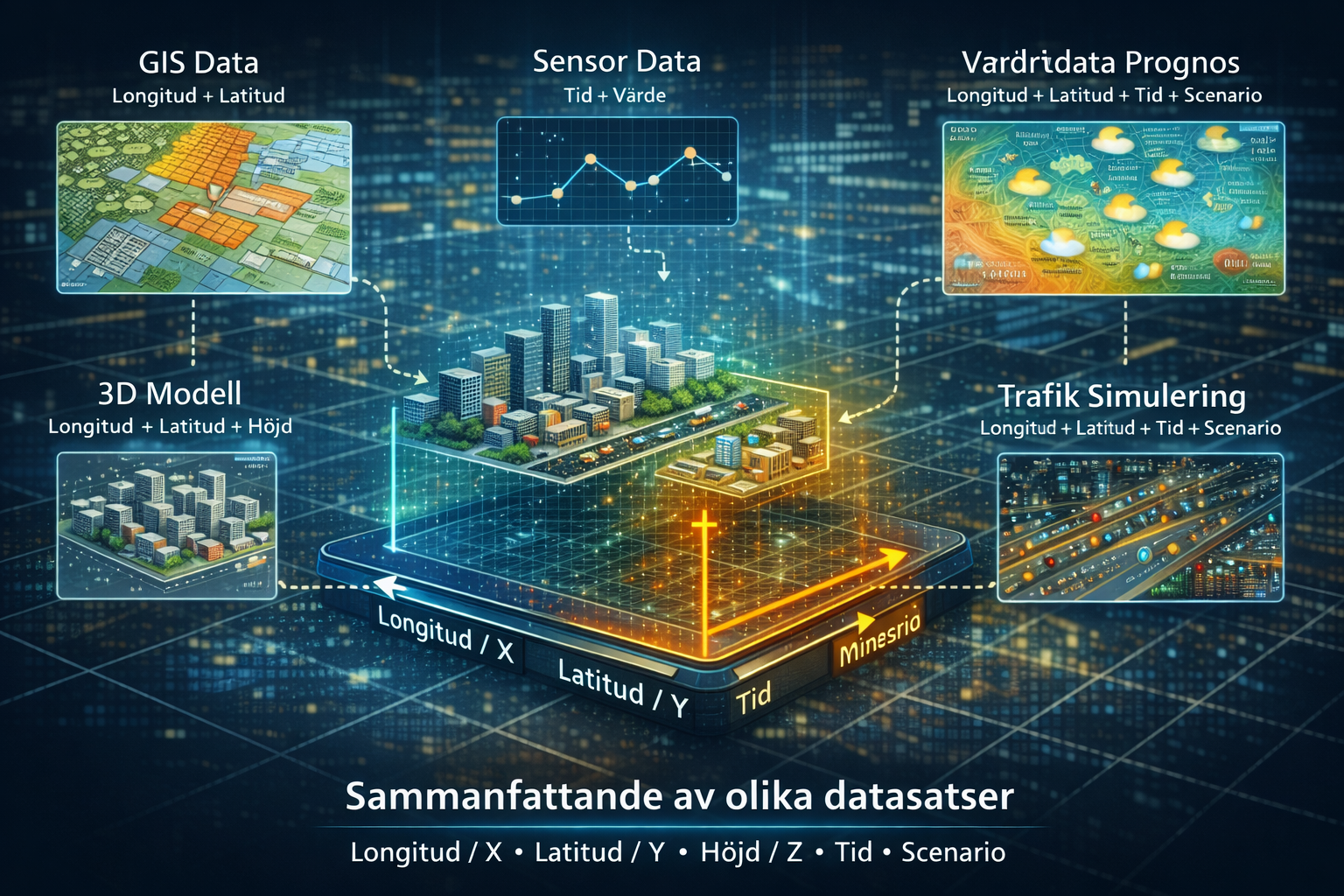
När vi arbetar med städer är GIS-data en av de vanligaste datatyperna vi stöter på. GIS-data beskrivs ofta i två dimensioner: longitud och latitud (alternativt X och Y beroende på koordinatsystem). I den meningen är den tvådimensionell. I planeringssammanhang handlar GIS-data dessutom ofta om framtida förslag, där det kan finnas flera alternativa scenarier. Då får vi två rumsliga dimensioner plus en scenariodimension – totalt tre dimensioner.
Sensordata har typiskt två dimensioner: tid och värde (till exempel temperatur, om det är en temperatursensor). Väderprognoser kan ses som data med en platsdimension (en punkt eller rutcell) och två tidsdimensioner: dels prognostid, det vill säga när prognosen utfärdades, och dels giltighetstid, det vill säga vilken tidpunkt prognosen avser. För en given plats säger prognosen alltså i praktiken: “utfärdad vid tid T₀, förväntat värde V vid tid T₁” (t.ex. temperatur). Prognoser är på så sätt nära besläktade med scenarion.
För 3D-modeller, exempelvis BIM, har vi normalt tre rumsliga dimensioner (X, Y, Z). Däremot har BIM ofta begränsat stöd för att hantera tid och scenarier på ett konsekvent sätt. Om vi i stället tar in simuleringsdata, till exempel trafik från verktyg som SUMO, får vi vanligtvis position över tid: ett fordon befinner sig på en viss plats vid en viss tidpunkt. Även här kan olika simuleringar representera olika scenarier.
När vi i projektet sammanfattade datatyperna såg vi att fem dimensioner återkommer i stadsplanering och blir särskilt viktiga när data ska sammanfogas i en digital tvilling. Dessa dimensioner beskriver var ett objekt befinner sig och när (och i vilket scenario) det ska existera eller visas:
- Longitud / X (beroende på koordinatsystem)
- Latitud / Y (beroende på koordinatsystem)
- Höjd / Z (beroende på koordinatsystem)
- Tid – när objektet börjar/slutar existera, när det befann sig på en viss plats, eller när det hade ett visst värde
- Scenario/prognos – vilken av flera möjliga framtider (eller alternativa förlopp) objektet hör till
Dessa dimensioner används för att beskriva objektens egenskaper som funktioner av plats, tid och eventuellt scenario. Exempelvis är trafikmängd på en viss plats en funktion av position, tid och ibland scenario. De fem dimensionerna ligger också nära hur vi kognitivt resonerar kring samhällsplanering: vid en viss tidpunkt såg en viss plats ut på ett visst sätt, och framtiden rymmer flera möjliga utvecklingar.
Utöver dessa dimensioner har varje objekt ett valfritt antal egenskaper och relationer till andra objekt. Både relationer, egenskaper och objektets 3D-position bör därför ses som beroende av objekt/plats samt vald tid och scenario.
Ett loggat fordons position är till exempel en funktion av tid, eftersom den förändras kontinuerligt. En persons ålder varierar över tid när personen blir äldre. En viss vägsträcka är kopplad till en byggnad men bara efter att byggnaden uppfördes. En planerad byggnads totala area kan bero på vilket av flera förslag (scenarier) man utgår från.
All data i en digital tvilling är med andra ord en funktion av tid och scenario. För sådant som redan har hänt finns oftast ett tydligt “huvudscenario” – det som faktiskt inträffade eller uppmättes. Men ibland vill vi också använda historiska data för att undersöka alternativa förlopp: hur hade det kunnat se ut om vi hade gjort annorlunda? Och mätte vi på rätt sätt?
En grundkurs kring objekt, egenskaper och dataset och kanaler
Ett objekt är en samling egenskaper. Vissa egenskaper saknar egen betydelse (t.ex. ålder), medan andra kan existera självständigt (t.ex. en adress). Självständiga egenskaper kan därför brytas ut till egna objekt och refereras via länkar.
Ett dataset är i grunden bara flera objekt samlade i samma meddelande eller fil.

Alla dessa – egenskaper, objekt och dataset – kan lagras på samma sätt: som innehåll i en adress (sökväg). Skillnaden ligger alltså inte i tekniken, utan i hur vi väljer att strukturera informationen.
📝
namn: Pelle 📝
ålder: 45📝
arbetsplats: RISE ______________
📝
namn: Sara📝
ålder: 52📝
arbetsplats: RISE ____________________📝
namn: Pelle 📝
ålder: 45📝
arbetsplats: RISE ______________
Vi kan öppna den 🔎 (om det är en fil 📄) eller prenumerera 🔔 på den (om det är en kanal/meddelandeström 📺).
Innehållet kan vara ett värde, en eller flera egenskaper (dvs ett objekt) eller ett dataset (flera objekt)– beroende på hur systemet är uppbyggt.
Adresser och åtkomst 🌍
Varje meddelandeström eller fil har en adress som gör att vi kan hitta den.
- Filer öppnas
- Meddelandeströmmar prenumereras på
Innehållet på en adress kan vara:
- en enskild egenskap
- ett helt objekt
- eller ett dataset
Detta gör att samma struktur kan användas konsekvent oavsett datans omfattning.
Exempel på ett meddelande som ett värde:
mqtt://server2/personer/per/properties/age → 45 Exempel på ett meddelande som innehåller flera varianter av samma värde:
mqtt://server2/trees/1/species → { "sv": "björk", "en": "birch" } Exempel på ett meddelande som innehåller flera egenskaper av samma värde:
mqtt://server2/personer/per → { "age": 45, "works at": "RISE" } Exempel på ett länkat objekt:
mqtt://server2/personer/per/street_adress → mqtt://server1/adresser/gatuadress/Sommarvägen 222 Där
mqtt://server1/adresser/postort/Sommarvägen 222/location → { "lat": 59.123, "lon": 18.456 }Att länka ihop data 🔗
Objekt kan länkas ihop över flera system. Det gör att vi kan samla all relevant information om ett objekt utan att bry oss om var datat finns.

Olika system kan ha olika data om trädet ovan. Trafikkontorets databas kan innehålla art och placering. När trädet planterades osv. Flygfoton han med årsintervallet ge oss data om hur trädet växt över tid. IoT sensorer kan ge oss realtids information om trädet behöver vattnas. En webbkamera kan användas för att att se om trädet har löv eller inte. När det tappade löven på hösten osv. Börjar men leta finns det oändligt med information om olika objekt i staden sprid över olika system.
- databaser (art, plantering, skötsel avtal, mm)
- IoT-sensorer (hälsa, fukt)
- kameror (lövsättning)
- flygbilder (tillväxt över tid)
Tillsammans bildar detta en helhetsbild genom länkade objekt.
mqtt://server1/trees/2312/location → mqtt://roadofficeserver.se/tree-database/2312/locationDär
mqtt://roadofficeserver.se/tree-database/2312/location → { "lat": 59.123, "lon": 18.456 }mqtt://server1/trees/2312/aerial-photos → gisdepartmentserver.se/aerial-photos/lat/59.12/lon/18.45/r/10/y/2024Vilket ger oss en bild 10m kring den aktuella punkten är från år 2024
mqtt://server1/trees/2312/moistrure→ mqtt://iot-server.se/sensor/34532/humiditydär
mqtt://iot-server.se/sensor/34532/humidity → {"time":"2025-05-14 13:45","humidity":44%}osv
Klicka här för fler exempel
Att dela upp datat ➗
De flesta dataformat och datameddelanden innehåller en hierarki, alltså en struktur som organiserar informationen. Precis som filer sorteras i mappar på en dator innehåller exempelvis en CityGML-fil en övergripande rotkatalog för hela modellen, följt av undernivåer för exempelvis byggnader, vägar och deras egenskaper.
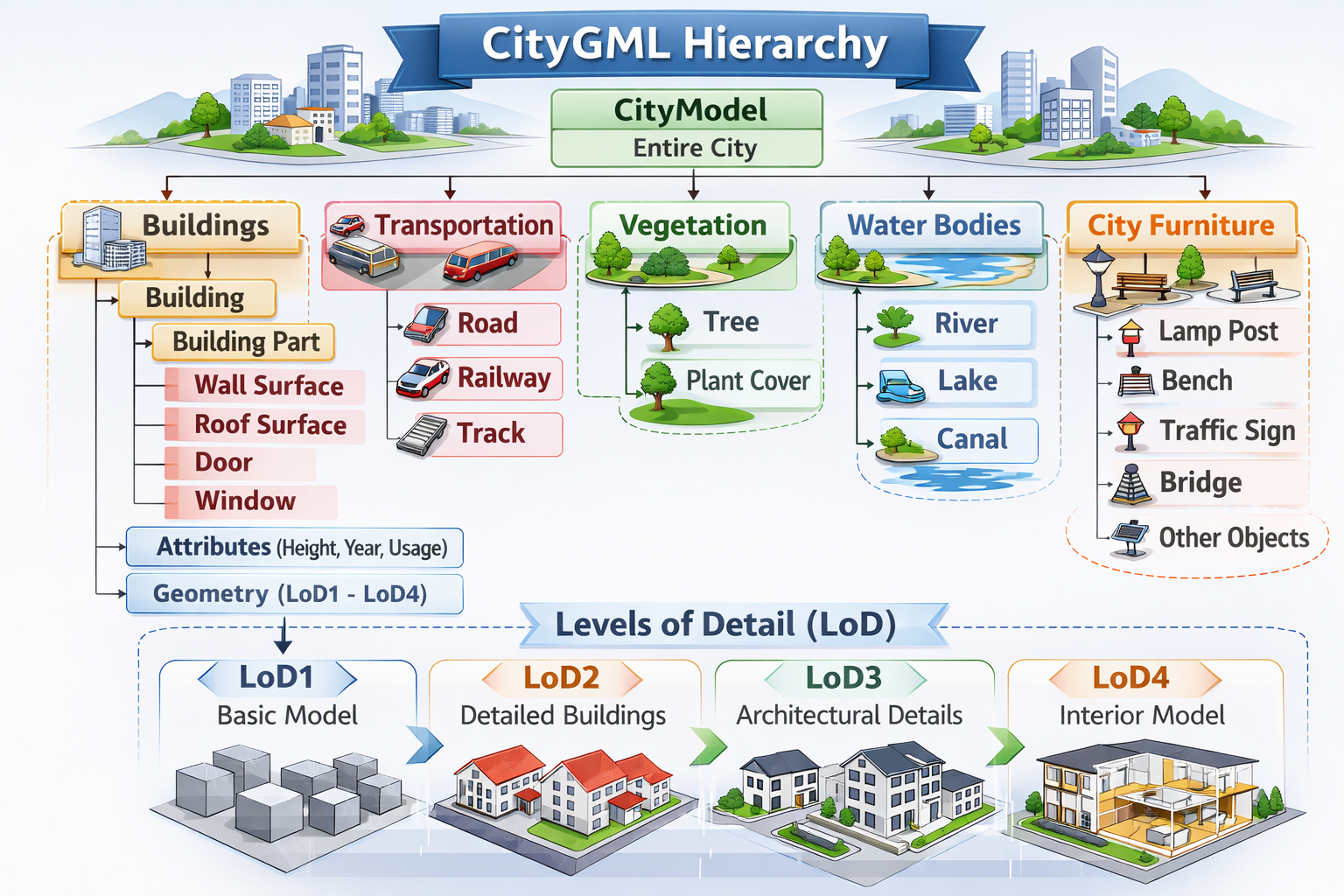
I teorin skulle vi kunna skicka en hel stad – exempelvis hela CityGML-filen med alla objekt och attribut – i ett enda meddelande i ett MQTT-topic. Ur ett realtidsperspektiv är detta dock ineffektivt. Vi vill ju inte behöva skicka en hel stad på nytt om en liten detalj ändras. Om vi har ett realtidstänk bör data brytas ned i så små delar som möjligt och endast skickas tillsammans när de är tidsmässigt kopplade. Om vi har en sensor som både har en temperatur och en fuktmätare vill vi att temperatur och fukt skickas som olika topics för att de inte är tidsmässigt bundet till varandra. Det finns ju inget som säger att en förändring i temperatur alltid sker samtidigt som en förändring i fukt sker även om de till viss del korrelerar. En tidstämpel däremot bör alltid skickas i samma meddelande som värdet på sensorn och har vi en elmätare så bör vi skicka både effekt, energi och tid i samma paket eftersom effekten och energin är matematiskt sammanbundna (Effekt = energi / tid).
En kanal per egenskap
Som nämndes ovan, om hela filen måste skickas varje gång en enskild egenskap ändras skulle stora datamängder överföras i onödan.
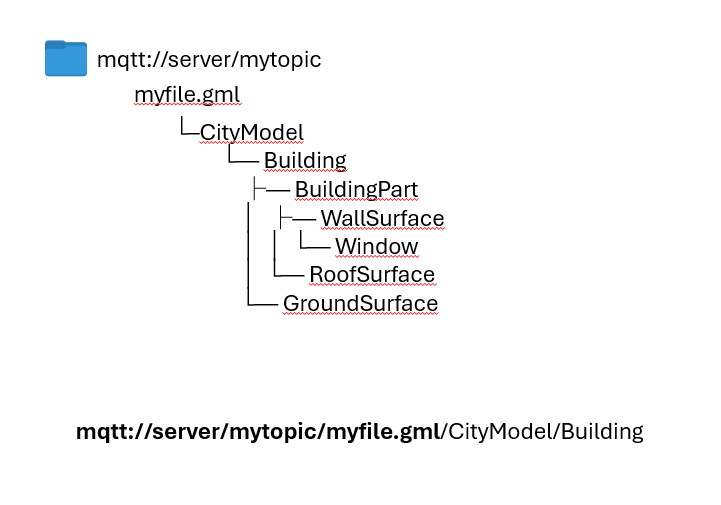
Därför valde vi i projektet att i de flesta fall skapa ett eget topic för varje enskild egenskap hos ett objekt. Ju mer data som grupperas tidsmässigt, desto mer information behöver skickas om och om igen trots att den inte förändrats.
Denna strategi medför dock vissa nackdelar. När en scen i en digital tvilling innehåller hundratals objekt och tusentals egenskaper uppstår ett stort antal förfrågningar, vilket innebär både tidskostnad och extra overhead i kommunikationen. En annan utmaning är behovet av att kunna exportera den uppdaterade originalfilen som datasetet bygger på.

För att hantera detta undersöktes flera strategier. En möjlighet är att låta datahubben cacha data (dvs lagra data från tidigare lokalt och använda den när det behövs igen tillsammans men frågor till servern om något har ändrats sen sist) eller att kunna hämta flera topics sammanslagna och komprimerade från servern (tex genom att ladda ner en zip-fil). En annan lösning är att göra originalfilen tillgänglig i ett eget topic och samtidigt skapa undertopics för objekt och egenskaper.
Om vi prenumierar på adressen: mqtt://server/mytopic/myfile.gml skulle vi då få hela gml filen. Medan om vi prenumierar på adressen: mqtt://server/mytopic/myfile.gml/CityModel/Building skulle i i stället få en enstaka byggnad i från filen.
När en egenskap uppdateras kan förändringen då återföras till huvudfilen, vilket gör det möjligt att både arbeta granulariserat i realtid och samtidigt behålla möjligheten att exportera en korrekt uppdaterad originalfil. Om vi tex då publicerar ett nytt värde till: mqtt://server/mytopic/myfile.gml/CityModel/Building/area
Så ändras även innehållet i mqtt://server/mytopic/myfile.gml
På det här sättet kan vi adressera objekt som finns inne i dataset.
En distribuerad 5-dimensionell realtidskunskapsgraf
För att förstå hur fenomen hänger ihop behöver vi kunna koppla samman objekt och deras egenskaper. En central funktion i ett digitalt tvillingsystem är därför att kunna länka objekt och följa samband över flera led.
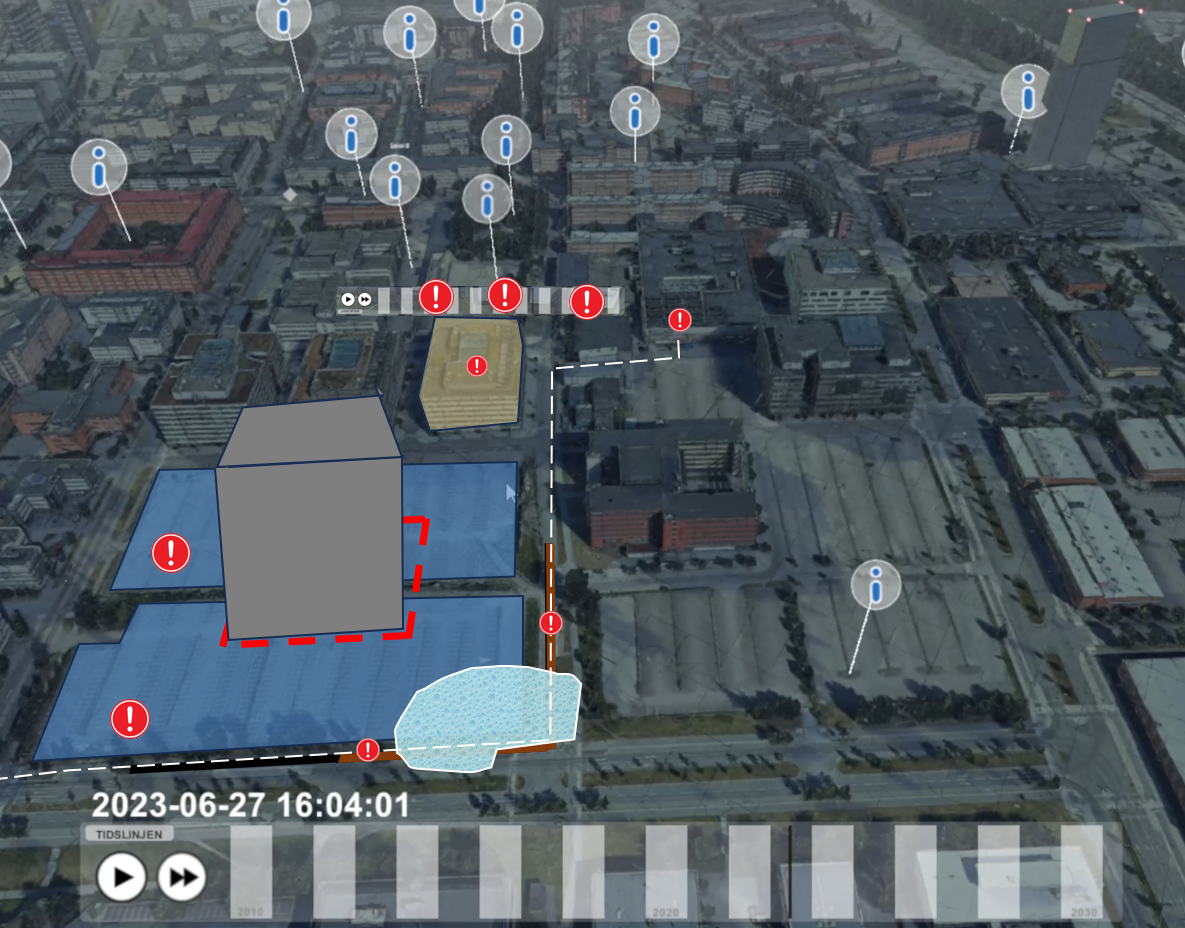
I figuren nedan visas hur sambandet mellan trafik på gatan och elförbrukning på ett kontor kan förklaras genom en kedja av relationer:
- Kamera är kopplad till sitt frustum (synfält).
- Frustumet överlappar ett visst vägavsnitt.
- Vägavsnittet är kopplat till en korsning och vidare till ett annat vägavsnitt.
- Detta vägavsnitt leder till husets källarparkering.
- Därifrån kopplas flödet vidare via hiss till kontoret och slutligen till elmätaren.
Kedjan gör det möjligt att förstå varför två till synes separata datapunkter ändå är relaterade och varför data som vi får från dem i någon mån bör korrelera.
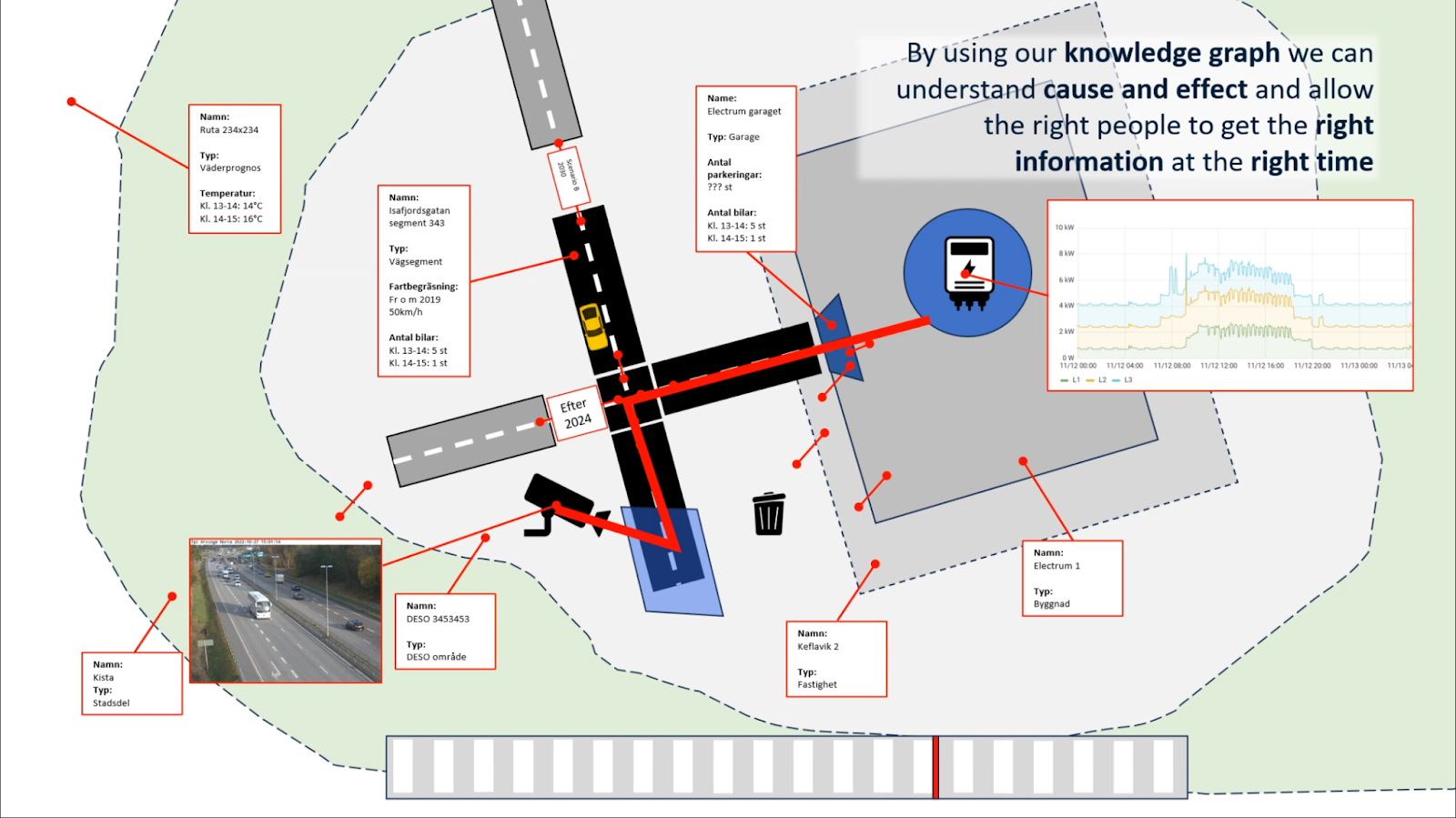
I projektet landade vi i att data bör lagras och hanteras som en distribuerad, femdimensionell realtids-kunskapsgraf. Begreppet kan brytas ned i tre delar, som tillsammans leder fram till våra designkriterier och motiverar implementationen.
Distribuerad
I en stad kan vi inte utgå från att all data ligger på samma server. Det beror dels på ägarskap och kontroll (olika organisationer vill behålla rådighet över sin data), dels på skala och volymer (det är svårt att samla allt centralt av kapacitetsskäl), och dels på arv och kontinuitet (befintliga system kommer att leva kvar under överskådlig tid).
Samtidigt vill vi kunna använda data som om den vore samlad: kombinera objekt där egenskaperna är spridda över flera system och ändå få en sammanhållen vy. Det förutsätter att vi kan länka data över systemgränser.
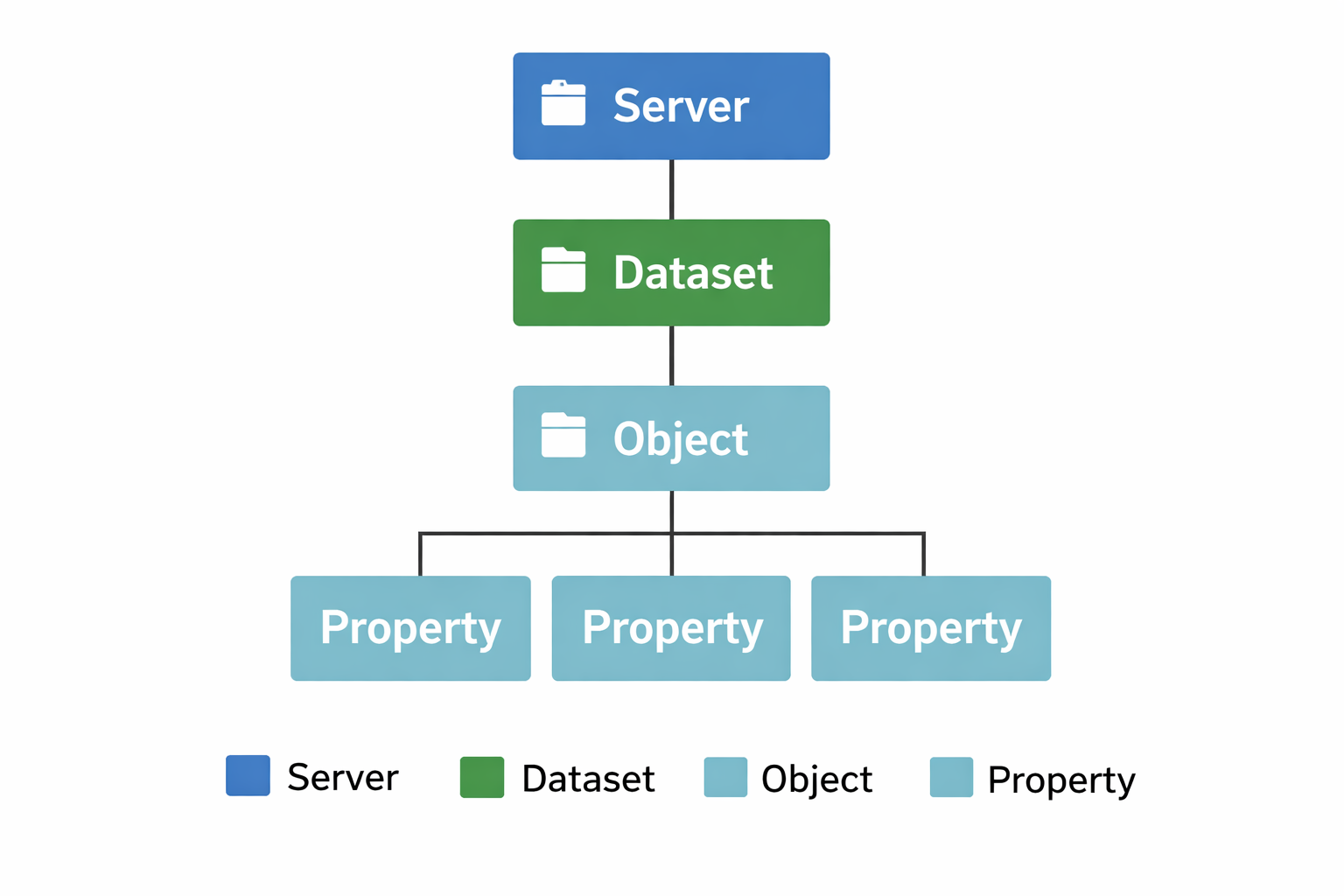
En nyckel för detta är en gemensam adressrymd, där objekt och egenskaper går att referera till entydigt med URL:er. Idag kan vi ofta peka på datasetnivå, men mer sällan på objekt- och egenskapsnivå. Principen kan illustreras så här:
- Dataset:
https://server/dataset/ - Objekt/egenskap:
https://server/dataset/objekt/egenskap
För att undvika en N-till-N-integration (varje ny applikation behöver integrera mot alla system) behövs ett mellanlager. I dataspace-termer motsvaras detta av connectors som exponerar data enligt en enhetlig standard och en separat broker som gör data sökbart. I vår ansats kan dessa funktioner antingen samexistera på samma server eller delas upp på olika servrar, beroende på hur strikt man vill följa dataspace-upplägget. Men vi vill mappa in de olika systemen som finns i dag på de olika mellanlagersservrarnas adress utrymme.
Videon visar hur antalet inegrationer som månste byggas och underhållas växer radikalt med antalet datakällor och appar. I ett alternativt scenario med ett mellanlager så blir situationen mera hanterbar.
Om vår mellan lager server är : https://mellanserver1.se/
Så kan vi tex mappa in ett GIS system som : https://mellanserver1.se/GISsystemet
Vi kommer då åt en egenskap genom adressen : https://mellanserver1.se/GISsystemet/dataset1/object/egenskap
Femdimensionell
Som vi diskuterat tidigare består stadsdata återkommande av fem centrala dimensioner: X, Y, Z, tid och scenario. För att kunna fungera som en “arbetsbänk” för sammanfogning och analys måste plattformen stödja dessa dimensioner konsekvent, så att egenskaper kan uttryckas som funktioner av plats och vald tid/scenario oavsett datakälla.
Realtid
Realtidsaspekten handlar inte bara om sensorer, utan om att förenkla helheten. Vissa källor uppdateras kontinuerligt medan andra uppdateras mer sällan, men om vi bygger separata system för “snabb” och “långsam” data skapar vi onödig komplexitet. Ett realtidsflöde blir därför den minsta gemensamma nämnaren: även långsamt uppdaterad data kan publiceras som händelser/uppdateringar, medan motsatsen ofta inte fungerar lika bra.
Som vi varit inne på tidigare stärker detta även samarbetet: i stället för att kopiera och sammanfoga data i efterhand kan man uppdatera vid källan och se ändringar direkt – mer som ett gemensamt dokument än flera separata filer som måste slås ihop med konflikter som resultat.
Designkriterier
Detta mynnade ut i följande designkriterier:
- Allt i systemet ska vara realtid (avsett uppdateringsfrekvens)
Om man någon gång har samarbetat i exempelvis Google Docs blir det tydligt varför: alla ser samma information samtidigt, istället för att arbeta i kopior som senare måste jämkas ihop. Vi eftersträvar samma direkthet i all datahantering. - Alla egenskaper modelleras som funktioner av tid och scenario (och vid behov plats).
- Objekt och egenskaper kan länkas inom och mellan system/servrar som en funktion av tid och scenario via en gemensam adressrymd (URL:er på objekt-/egenskapsnivå).
- Nya system kan integreras och exponeras via ett mellanlager för att undvika N-till-N-kopplingar.
- En enhetlig åtkomst till data
Vi vill minimera antalet sätt att komma åt data. Istället för att integrera mot många olika servrar och protokoll låter vi datakällor ansluta till ett gemensamt mellanlager. Därifrån nås all data på ett enhetligt sätt – oavsett om det handlar om historisk data eller realtidsdata, och oavsett datatyp (GIS, sensordata, statistik eller annat).
Målet i projektet var inte att bygga en slutgiltig plattform, utan att snabbt ta fram en prototyp där dessa principer kunde testas och verifieras. I nästa avsnitt går vi därför över till hur vi valde att implementera detta i praktiken.
Vår prototyp
När vi skulle välja grundplattform vår digital tvilling var det två grundläggande principer som vägde extra tungt:
- Allt i systemet ska vara realtid
Om man någon gång har samarbetat i exempelvis Google Docs blir det tydligt varför: alla ser samma information samtidigt, istället för att arbeta i kopior som senare måste jämkas ihop. Vi eftersträvar samma direkthet i all datahantering. - En enhetlig åtkomst till data
Vi vill minimera antalet sätt att komma åt data. Istället för att integrera mot många olika servrar och protokoll låter vi datakällor ansluta till ett gemensamt mellanlager. Därifrån nås all data på ett enhetligt sätt – oavsett om det handlar om historisk data eller realtidsdata, och oavsett datatyp (GIS, sensordata, statistik eller annat).
Som fundament för systemet och mellanlagret valde vi ett enkelt, välkänt och beprövat realtidssystem: MQTT
MQTT används ofta för att koppla samman realtidssystem och kan liknas vid en chattserver för data. På servern skapas “rum” (💬 topics) där processer publicerar information, och där valfritt antal klienter kan prenumerera och ta del av samma data i realtid.
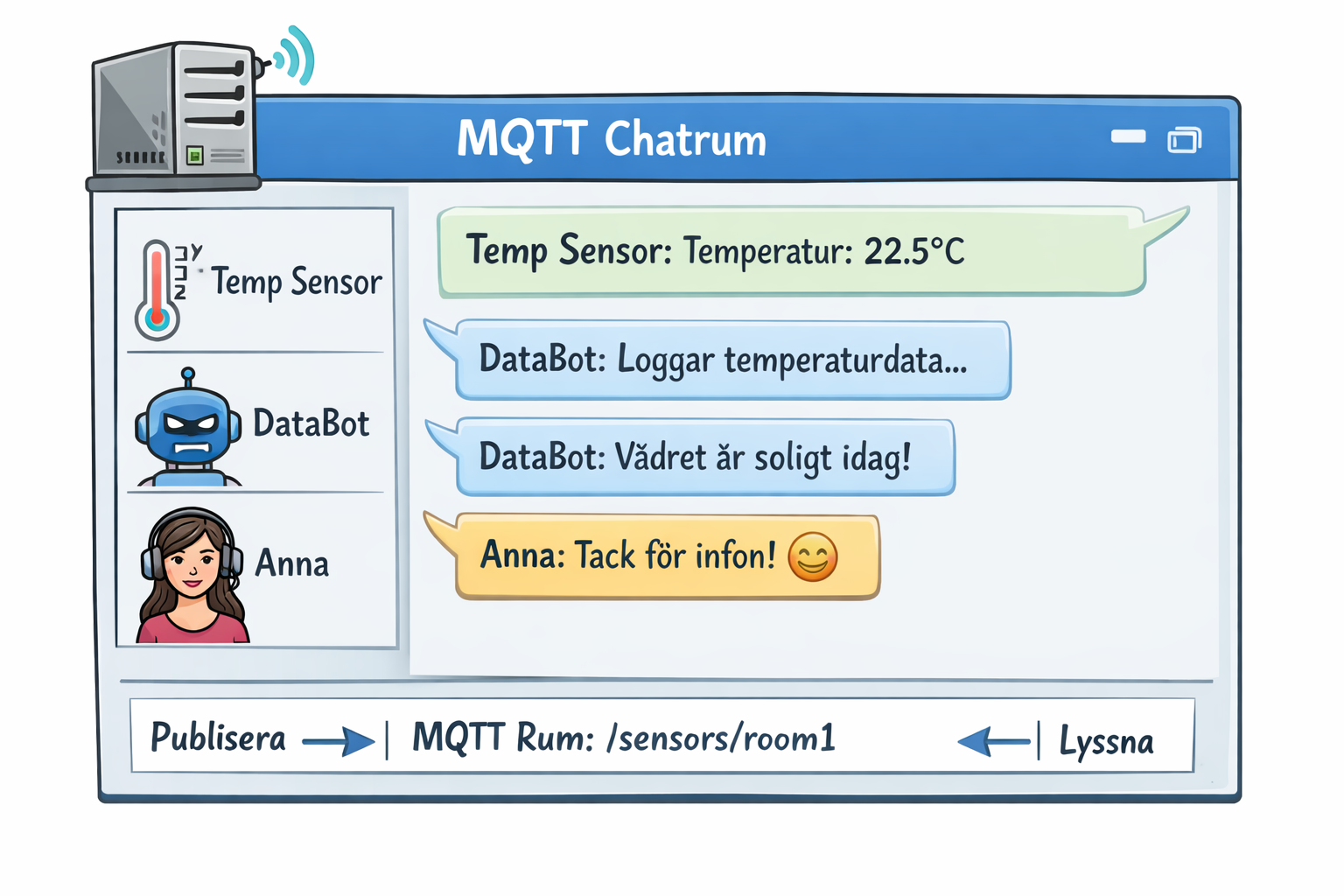
Varje server kan innehålla ett i princip obegränsat antal sådana rum, så kallade topics, som namnges som hierarkiska sökvägar. Ett exempel kan vara:
💬pelles hus/vardagsrum/stereo anläggning/elförbrukning
Videon illustrerar hur en MQTT broker fungerar
Vi kan beskriva dessa topics som “chattrum”, men de kan också förstås som kanaler eller som filer och mappar i ett filsystem. En viktig skillnad jämfört med traditionella filer är dock att vi kan få en uppdatering direkt när innehållet förändras, istället för att aktivt behöva hämta det.
MQTT är i grunden en enkel teknik och saknar många av de mer avancerade funktioner som ofta efterfrågas i en plattform för digitala tvillingar. Samtidigt var det just denna enkelhet som gjorde lösningen attraktiv. Genom att utgå från ett avskalat protokoll kunde vi själva utforma de funktioner som behövdes, utan att begränsas av färdiga ramverk eller förutbestämda arbetssätt.
En stor del av projektets experimentella arbete handlade därför om att undersöka hur vi kan bygga vidare på och utöka denna grund – för att skapa ett system som i grunden är realtidsbaserat, men samtidigt tillräckligt flexibelt för att hantera komplexa behov i en digital tvilling. I exemplen här under kan du få en inblick i hur vår lösning kom att fungera.
Vi ser både hur olika chattrum triggar olika former av visualiseringar genom att de finns och att innehållet i dem styr själva visualiseringen.
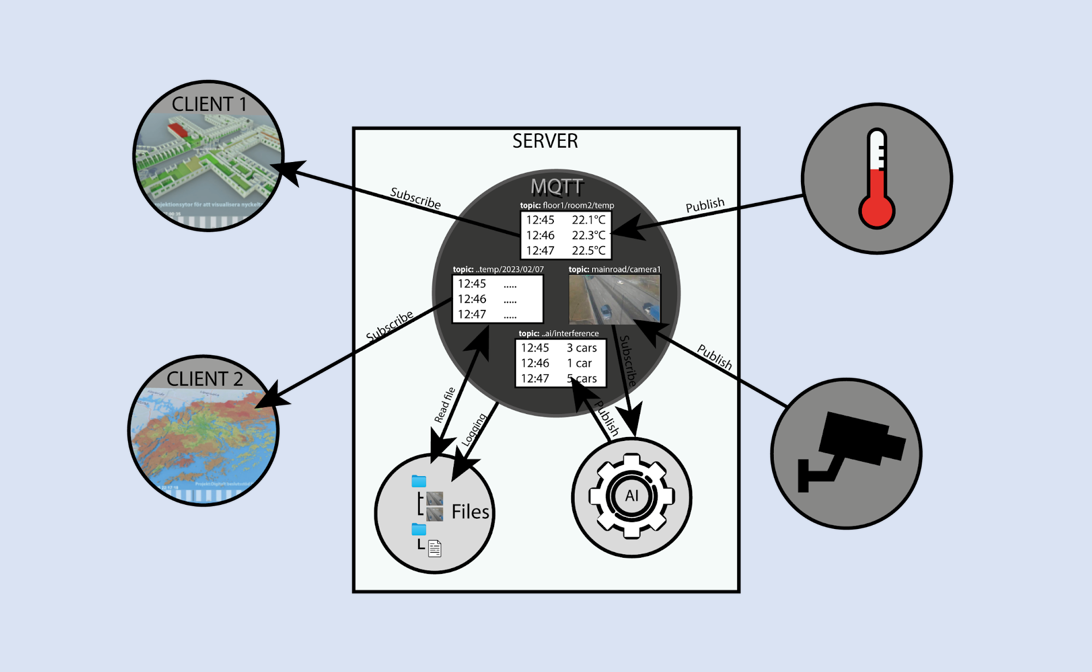
Vi ser också ett exempel på dataflödet mellan olika sensorer, processer och användarens klient.
För att skapa en fullfjädrad digital tvilling plattform var det dock många frågor som vi måste hitta svaren till. Tex:
- Hur mappar vi in data i brokern från andra system?
- Hus skapar vi en gemensam adressrymd för all data ner på egenskapsnivå?
- Hur gör vi så att man kan söka topics och data i systemet?
- Hur hanterar vi historisk data och olika framtidsscenarion?
- Hur beskriver vi scener och objekt i den digitala tvillingen?
- Hur gör vi systemet effektivt?
Låt oss börja med att titta på de två första frågorna.
En gemensam adressrymd i MQTT 🔭
I vår lösning utgör MQTT själva kärnan, men vi har samtidigt velat möjliggöra en gemensam adressrymd som sträcker sig över flera servrar. I standardanvändning av MQTT refererar man ofta enbart till ett topic, utan att ange vilken server det tillhör, eftersom kommunikationen vanligtvis sker mot en enskild broker i taget.
tex: 💬pelles hus/vardagsrum/stereoanläggning/elförbrukning
För att hantera en distribuerad miljö använder vi därför fullständiga URL-adresser för att identifiera topics, där även servernamnet ingår. Exempelvis:
🌍mqtt://server1.ri.se/pelles hus/vardagsrum/stereoanläggning/elförbrukning
🌍mqtt://server2.stockholm.se/miljöparameterar/totalautsläppstaden
På så sätt kan data från olika servrar uppfattas som en sammanhängande helhet. I alla lösningar som vi utvecklade så började vi därför att genomgående använda fullständig URL:er.
För att ansluta befintliga datakällor och kunna adressera objekt och egenskaper i dessa behövs två saker :
- En konsekvent URL-struktur för datasettet där olika delar kopplas in i olika "chattrum"
- Ett skript som kopplar datakällan till MQTT-lösningen
Låt oss ge ett exempel på en URL-struktur. Anta att vi definierar följande adress för att komma åt data om stadens stadsdelar och deras storlek:
🌍mqtt://testserver.stockholm.se/GIS-data/stadsdelar/[STADSDELSNAMN]/[EGENSKAP]
Detta skulle göra att vi kommer åt storleken på Kista med adressen:
🌍mqtt://testserver.stockholm.se/GIS-data/stadsdelar/Kista/yta
Vi kan nu gå över till steg två dvs skapa vårt skript för att koppla in data från stadens existerande system till vår broker.
Om man går in på dataportalen.stockholm.se så kan vi söka på stadsdelar man får då upp följande information:
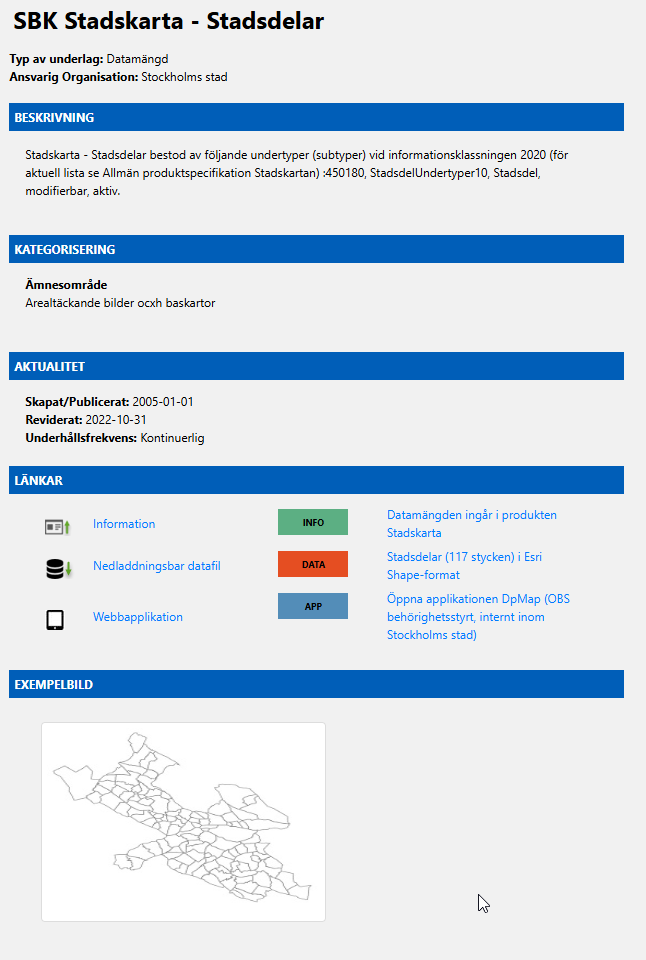
För att manuellt komma åt en egenskap på ett objekt i datasettet så behöver vi:
- Ladda ner datasetet som zip-fil.
- Packa upp och öppna shapefilen i ett GIS-verktyg.
- Hitta rätt objekt och läsa dess egenskaper.
- Kontrollera regelbundet om datasetet har uppdaterats och upprepa processen vid behov.

På liknande sätt konstruerar vi vårt skript som ska mappa datat i datasettet i vår adressrymd och utforma det till att göra detta åt oss automatiskt.
Vårt skript kommer då att:
- Lyssnar på om någon klient börjar prenumerera på:
🌍mqtt://testserver.stockholm.se/GIS-data/stadsdelar/[STADSDELSNAMN]/[EGENSKAP] - Om någon gör det så kontrollerar vi om vi har kvar cachad data för det aktuella objektet från en tidigare prenumeration. Detta är viktigt då inte alla system som finns idag är dimensionerade för en framtid där alla i en stad jobbar datadrivet. På det här sättet kommer vårt mellanlager också att avlasta existerande system.
- Om vi har en tidigare kopia så uppdaterar vi klienten med det. Ifall URL:en är:
mqtt://testserver.stockholm.se/GIS-data/stadsdelar/Kista/ytaså publicerar vi värdet:4471759 m²till samma adress. Direkt därefter kollar vi om datat reviderats sedan vi senast laddade ner det. Tex genom att kontrollerar revisions datum på dataportalen (se bilden ovan från dataportalen). - Om revisionsdatumet i dataportalen för det aktuella datasettet har ändrats eller om vi inte har en tidigare kopia så laddar vi ner hela datasettet (på nytt) och extraherar det. Vi kollar därefter om det specifika värdet som klienten efterfrågar har ändrats och publicerar det nya värdet om det har.
- Så länge någon prenumerera på något av URL:erna under:
mqtt://testserver.stockholm.se/GIS-data/stadsdelar/så fortsätter vi att regelbundet kontrollera revisionsdatumet på dataportalens hemsida och publicera nya uppdaterade värden om den ändras.
På detta sättet kan klienten snabba på data men hela tiden anta att de har det senaste och mest uppdaterade datat (i alla fall ett kort tag efter det initiala värdet har anlänt). Liknande skript som detta kan på det här sättet göras för olika datakällor. Ett skript som tex laddar data från en WFS sever kan ofta till stor del återanvändas till andra servrar med samma dataformat.
Varje skript behöver naturligtvis vara byggd för det det aktuella dataformatet som en viss datakälla har men i övrigt är logiken densamma med ett undantag. Detta gäller datakällor som inte själv lagrar historiska data men där vi vill att detta ska finnas. Vi kan då behöva modifiera skriptet så att det inte bara cachar de senate efterfrågade värdena utan också lagrar historiska värden i en databas. I dessa fall kommer vårt skript att behöva hämta in data kontinuerligt oavsett om någon prenumererar på datat eller inte.
Förutom datakällor så har vi på liknande integrerat olika AI tjänster både för bildigenkänning (tex räkna bilar på trafikkameror som i exemplet ovan) och chatbottar så som ChatGPT och liknande.
Med ovan lösningar i MQTT kan vi mappa in olika existerande system i en gemensam adressrymd och adressera objekt och egenskaper i olika undersystem som vi integrerar med en prenumerationslösning. Under projektets gång har vi sedan byggt upp olika sökvägar där olika data finns att tillgå. Det finns tex en sökväg där bilder från trafikkameror på trafiken.nu publiceras, det finns en sökväg för att hitta väder och temperatur från SMHI det finns en annan sökväg för att hitta data från SCB, en för att hämta ner ett visst område av lantmäteriets flygfoton för ett visst år, ett för google streetview osv.
Flera tjänster kan ligga på samma server men vi kan också dela upp det så att viss data ligger på en server och viss annan data på en annan. Vi har också byggt ett antal plugins som gör att vi kan ladda in en 3d modell i 3d programmet Blender. Modifiera modellen publicera den varpå alla som tittar på modellen i andra program tex en annan Blender instans eller våran digitalatvilling plattform i realtid får se uppdateringen. Vi har också gjort en integration mot Excel där vi kan ladda objekt och deras egenskaper som tabeller. När man ändrar en egenskap så updateras den hos alla som prenumerera på den oavsett vilket program man använder.
Videon visar hur användaren väljer en av medlemmarna i gruppen och egenskapen ålder och sendan kopierar sökvägen. I nästa vy så klistrar användaren i samma sökväg i Excel och får då samma värde som visades i tvillingen. Om värdet ändras i någon av applikationerna kommer det direkt att återspeglas i de andra applikationerna.
Som utvecklare av tjänster i staden får vi det på det här sättet mycket lättare att bygga lösningar som sätter samman flera olika datakällor från flera olika system och dataset på en objekt och egenskaps nivå samt ser till att vi tittar på samma data. Detta är grunden för att bygga system som hjälper oss minska tunnelseendet när vi tar beslut och utformar vår miljö.
🔍 Sökfunktioner i MQTT
På samma sätt som vi kan skapa skript som kopplar vår adressrymd till befintliga datakällor så kan vi också skapa egna lokala datatjänster. En sån är funktioner för att söka i datat. Vi har i det här projektet utvecklat två sådana sökfunktioner.
En av dessa sökfunktioner tillåter användaren att få en lista på alla underkanaler som finns till en viss kanal.
Medan en prenumeration på:
💬mqtt://testserver.stockholm.se/GIS-data/stadsdelar/Kista/yta
ger oss talet 4471759 m² i exemplet ovan så ger en prenumeration på
💬mqtt://testserver.stockholm.se/GIS-data/stadsdelar/Kista/ (dvs med ett / på slutet av adressen ) oss en lista på alla egenskaper som finns för Kista. Tex ["yta/","shape/","name/"].
Detta ger oss vetskapen att det finns alla dessa kanaler:mqtt://testserver.stockholm.se/GIS-data/stadsdelar/Kista/yta
mqtt://testserver.stockholm.se/GIS-data/stadsdelar/Kista/shapemqtt://testserver.stockholm.se/GIS-data/stadsdelar/Kista/name
Detta används av klienter för att kunna lista alla objekt i tex en scen som ska visualiseras eller för att att lista och skapa auto-complete funktioner när man navigerar adressrymden. I exemplet tidigare där vi kunde se hur olika kanaler på ett objekt triggade olika typer av visuliseringar så används denna just för att klienten ska veta hur objektet ska visualiseras i tvillingen. Om vi tex har en kanal som heter POI så genereras en point of interest icon som pekar på det aktuella objektet i scenen.
En annan av dessa sökfunktioner tillåter användare och skript att fritt söka bland alla chattrum. Denna funktion används för att koppla tjänster till olika chattrum. Vi kan tex lägga inställningar för en algoritm i kanalen:
💬mqtt://server.se/trafik/kamera1/YOLO.cfg
En tjänst som räknar bilarna med YOLO algoritmen kan då söka av servern efter alla kanaler som slutar på YOLO.cfg och köra algoritmen på data i föräldrakatalogen dvs: mqtt://server.se/trafik/kamera1
Med inställningarna som den hittar i kanalen YOLO.cfg. Vi han där tex ange till vilken kanal som resultatet ska postas och vilka objekt den ska söka efter.
🏛️Historisk data i publish subscribe
En central utmaning var att hantera historisk data i ett publish/subscribe-system. Den typen av arkitektur är i första hand anpassad för realtidsdata, medan historik vanligtvis hämtas från en tidsseriedatabas. I praktiken innebär det att applikationsutvecklare måste arbeta med flera protokoll och dessutom synkronisera realtidsströmmen med historiska data från databasen. I projektet ville vi därför undersöka om detta kunde lösas på ett mer enhetligt sätt.
Ett relaterat problem är hur aggregerad data hanteras. I många tidsseriedatabaser beräknas till exempel tim-, dygns- eller månadsvärden först vid själva förfrågan, genom att räkna ut medelvärde, max eller min för en given period. Dessa beräkningar kan vara relativt tidskrävande. I en digital tvilling, där användaren förväntas kunna röra sig snabbt fram och tillbaka i tiden, riskerar detta att leda till oacceptabla svarstider.
Vår slutsats blev därför att det i detta sammanhang är mer effektivt att arbeta med fasta, i förväg beräknade värden – exempelvis per timme, dygn, månad och år. Det möjliggör snabbare respons och en mer interaktiv upplevelse. Nackdelen är att flexibiliteten minskar: vi kan inte längre fråga efter godtyckliga tidsintervall, utan måste antingen hålla oss till de fördefinierade perioderna eller kombinera flera sådana.
Om vi till exempel har en elmätare kan vi direkt se förbrukningen för en specifik timme eller för ett helt år. Vill vi däremot veta förbrukningen under de senaste fyra timmarna behöver vi hämta varje timvärde separat och summera dem.
🧵 Underkanaler för historik
Vi behöver också ett sätt att mappa in historisk data i vår adressrymd. Lösningen blev att skapa underkanaler till varje kanal som innehåller historiska data. För detta utvecklades ett TimeIndex-skript som publicerar en loggfil för varje timme i en underkanal till originalkanalen.
När data publiceras på exempelvis
💬mqtt://server1/datadirectory/min-katalog/signalA
skapas automatiskt ett underkanalen:
💬mqtt://server1/datadirectory/min-katalog/signalA/TimeIndex.
Här lagras loggfiler enligt tidsstämplar i formatet:YYYY/MM/dd/HH/.
Exempel: Om ett värde publiceras kl. 12:05 den 1 april 2024 lagras det iTimeIndex/2024/04/01/12/1711972800.jsonl
där tidstämpeln 1711972800 representerar tiden för kl. 12:00 den aktuella dagen dvs tiden loggfilen gäller från.
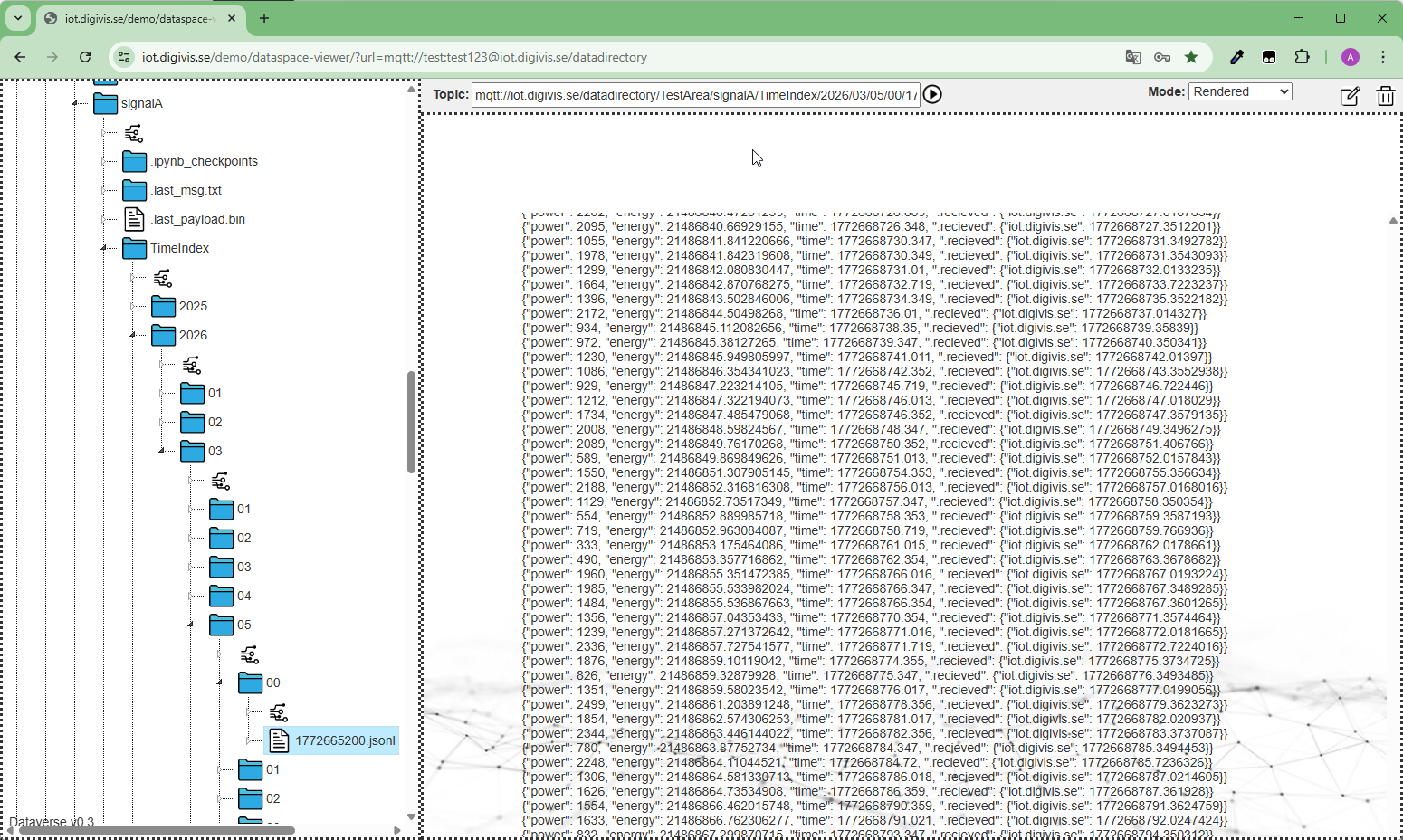
För bilder används i stället en tidsstämpel per publicering, exempelvis:TimeIndex/2024/04/01/12/1711965900.jpg. I detta fall är tidstämpel tiden då bilden togs eller om det inte finns tillgängligt tiden som bilden kom in till servern.
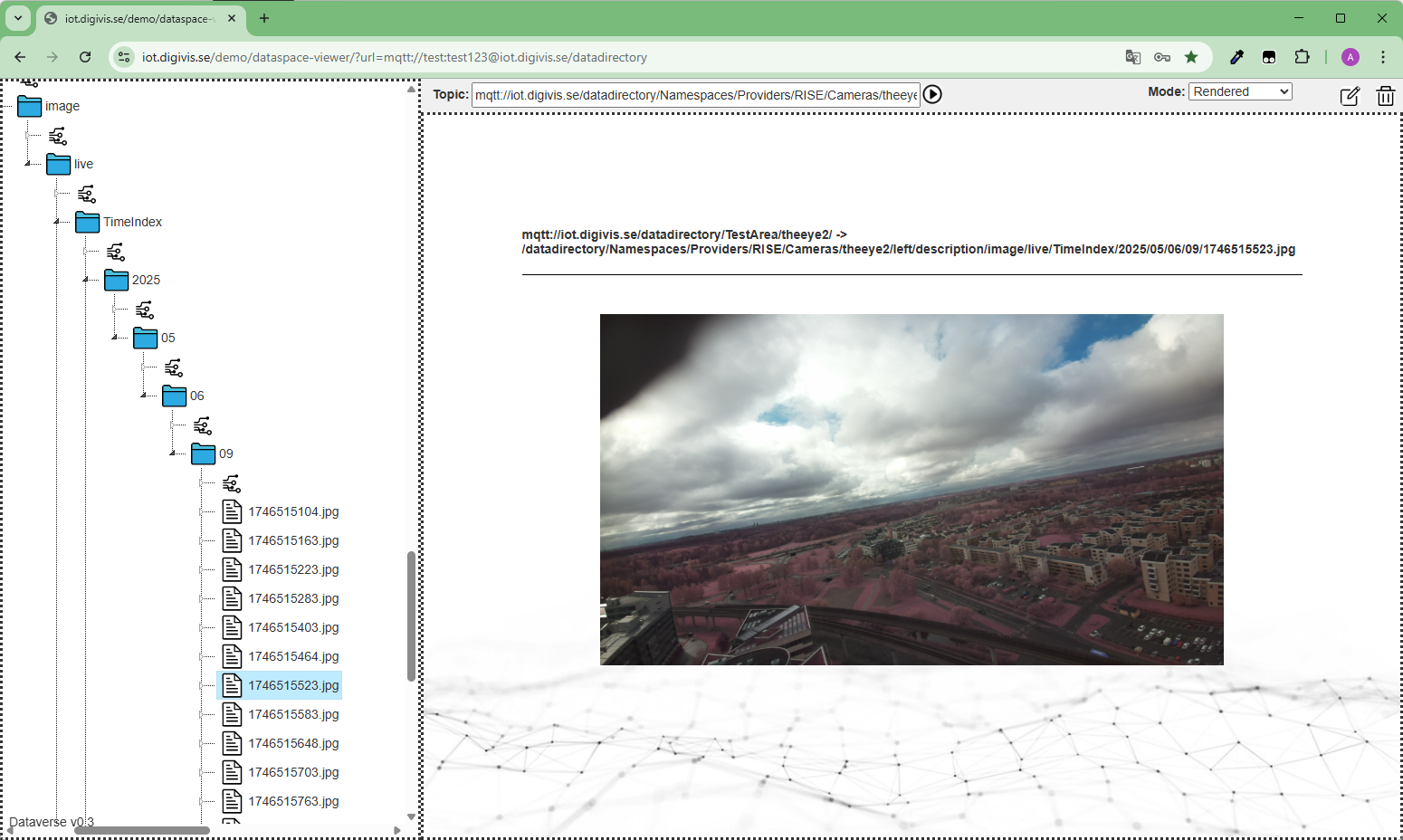
Det innebär att det för:
- Datavärden finns max en loggfil per timme (JSONL).
- Bilder/film kan finnas flera filer per timme.
De överliggande katalogerna används för att beräkna nyckeltal för år, månad, dag och timme.
Scenarion
Med en fyrdimensionell digital tvilling så är alla värden en funktion av tiden. Om vi skapar en femdimensionell digital tvilling med olika framtida scenario så kommer ett värde att vara en funktion av både tiden och valt scenario. På liknande sätt skapades därför ett ScenarioIndex som möjliggör scenariobaserade tidsserier. Om ingen scenariodata finns används standardvärdet i TimeIndex kanalerna. Tex.:signalA/TimeIndex/2024/04/01/12/1711972800.jsonl.
Men om exempelvis följande fil finns:ScenarioIndex/ScenarioB/signalA/TimeIndex/2024/04/01/12/1711972800.jsonl
ersätter den originalfilen ovan när ScenarioB är aktivt i den digitala tvillingen.
Denna modell gör det möjligt att hantera realtidsdata, historik och scenariovarianter inom samma publish/subscribe-struktur. I de klienter som vi använder för att komma åt datat så hanteras detta utan att vi som användare behöver veta detaljerna. Vi gör helt enkelt bara en förfrågan för en viss kanal men med tid och scenario som parametrar.
datahub.Subscribe(topic,time,scenaio,handler)
Klientverktyg
För att förenkla utvecklingen tog vi fram flera lokala bibliotek i olika programspråk för att kommunicera med vårt system samt ett koncept som vi kallar Datahubben.
Videon illustrerar funktionen av datahubben
När man bygger applikationer, till exempel en enkel dashboard, uppstår ofta behov av att flera widgetar hämtar data från en eller flera servrar. Utvecklaren måste då hålla reda på vilken server varje förfrågan ska gå via och se till att komponenter som använder samma server delar på en och samma anslutning. Annars riskerar applikationen att skapa flera parallella anslutningar till samma server.
Datahubben eliminerar detta behov genom att låta klienten prenumerera på data utan att hantera anslutningar manuellt. Den kontrollerar automatiskt om en anslutning till aktuell server redan finns och skapar en ny vid behov. Om flera lokala moduler efterfrågar samma data distribueras inkommande meddelanden till samtliga prenumeranter via samma anslutning.
Datahubben kan både hantera prenumerationer på topics och publicering av data. Klienten skickar den fullständiga URL:en till Datahubben, som därefter:
- Kontrollerar om en anslutning till servern redan finns.
- Skapar anslutning och prenumeration om den saknas.
- Lägger till en ny prenumeration om anslutningen redan existerar.
- Distribuerar inkommande meddelanden till rätt lokala moduler.
Resultatet är en lokal lösning där många moduler kan hämta data från flera datakällor samtidigt, men där varje server endast har en aktiv anslutning per applikation. Som användare behöver man inte längre veta var datat finns – man startar Datahubben, laddar in sina inloggningsuppgifter till servrarna och prenumererar därefter direkt på den URL som innehåller önskad data.
Med Datahubben och vår gemensamma adressrymd uppfyller vi ett centralt designmål: Att data från flera olika servrar och dataset kan användas som om allt låg på en och samma server, via ett enhetligt protokoll samtidigt som informationen hålls automatiskt uppdaterad och synkroniserad mellan alla användare.
Modifieringar av MQTT
För att kunna integrera andra system med vår MQTT-broker har vi gjort ett antal anpassningar. Grundtanken i MQTT är att den som publicerar data inte behöver känna till mottagarna. Producenter och konsumenter är helt separerade: producenten publicerar data på en kanal och konsumenterna prenumererar kanalen om de vill ha den aktuella datan. När ny data publiceras får alla prenumeranter den direkt.
Ett problem uppstår när en klient varit frånkopplad. Den kan då ha missat senaste värdet. Om producenten bara publicerar exempelvis en gång i timmen kan användaren behöva vänta länge på nästa uppdatering. MQTT hanterar detta genom retained messages, där senaste värdet sparas i brokern och skickas direkt till nya prenumeranter som ansluter.
Detta är effektivt men innebär att retained-meddelanden lagras i serverns RAM-minne. Om retained används i stor skala, särskilt med stora meddelanden, kan minnet snabbt bli fullt.
Om vi ska mappa in all staden data så skulle vi med andra ord behöva publicera all data från stadens system till serverns RAM-minne i förväg för att göra det direkt tillgängligt. För att komma runt det så har vi utvecklat en alternativ lösning.
Prenumerationsdriven datainhämtning
Även om dataproducenter normalt jobbar oberoende av data konsumenter i MQTT så finns här med andra ord en anledning för undantag. Vid dessa tillfällen vill vi inte att producenterna producerar data förrän det finns en klient som prenumererar på den aktuella kanalen.
För att få till det skapade vi ett skript som övervakar MQTT-interna loggar och publicerar alla nya prenumerationer till kanaler som en egen dataström. Om exempelvis klient1 prenumererar på testsignal/A publiceras ett meddelande på $subscriptions/testsignal/A med klientens ID.
Detta gör det möjligt att skapa ett dataintegrationsskript (även kallad dataconnector) som triggar först när en klient begär datat.
Om en klient prenumererar påmqtt://server1/GIS-systemet/stadsdelar/Kista/yta
publiceras samtidigt ett meddelande påmqtt://server1/$subscriptions/GIS-systemet/stadsdelar/Kista/yta.
Dataconnectorn för GIS-systemet prenumererar påmqtt://server1/$subscriptions/GIS-systemet/#
(där # betyder samtliga underkanalen) och kan därmed reagera på alla efterfrågade objekt och egenskaper. Den hämtar relevant data och publicerar den på rätt topic. Så länge prenumerationen finns kan dataintegrationsskriptet även periodiskt kontrollera om data förändrats och publicera uppdateringar vid behov.
Resultatet är en övergång från en REST-modell med kontinuerliga polling-förfrågningar till en publish/subscribe-modell där endast dataconnectorn behöver göra periodiska kontroller.
Precis som vanliga kanaler han vi styra vem som får se medelandena om vilka som ansluter till kanalerna på olika ställen på servern.
Privata topics i stället för retained
Den andra förändringen är införandet av ett privat topic för varje topic. I stället för retained-meddelanden har våra datahubbar (C#, Python och JavaScript) byggts om så att de automatiskt prenumererar på två topics:
- Det publika topicet
- Ett privat topic:
$private/<clientid>/...
Om en klient prenumererar påmqtt://server1/GIS-systemet/stadsdelar/Kista/yta
skapas även en prenumeration påmqtt://server1/$private/<clientid>/GIS-systemet/stadsdelar/Kista/yta.
Dataconnectorn publicerar senaste värdet till den privata kanalen, så att en nyansluten klient omedelbart får aktuell data. Den publika kanalen används endast för nya uppdateringar, exempelvis om Kistas yta ändras i GIS-systemet och alla anslutna klienter behöver få veta att värdet har ändrats.
Denna lösning minskar minnesanvändningen, eliminerar behovet av retained-meddelanden och gör det möjligt att hämta data först när den efterfrågas.
Data lagring av den 5D dimensionella kunskapsgrafen
I vårt strävan efter att utforska det optimala systemet för att driva digitala tvillingar och datadrivna samarbeten upptäckte vi ganska snart att vi behövde ha lagringsutrymme för nya dataset. Detta kan vara katalogdata över existerande data eller olika indexeringar tex alla objekt från ett antal dataset som finns i ett visst område osv. Det kan också vara en lagrings yta för arbetsgrupper, projekt och scener i den digitala tvillingen. Vi behöver i bland även komplettera de existerande systemen som finns. Ett sånt exempel är trafiken.nu, är att de saknar historisk lagring av sina bilder från tex trafikkameror och TA-planer (dvs där vägen ska stängas av).
För detta skapade vi en särskild lagringsyta på servern, kallad datadirectory, där objekt och relaterad data kan sparas. Denna yta synkroniseras direkt mot en disk på servern, vilket innebär att ett MQTT-topic som exempelvismqtt://server1/datadirectory/min-katalog/signalA
mappas till motsvarande filstruktur på servern:min-katalog/signalA.
Det är möjligt att använda en databas i stället för filsystem, men för prototypen var en filbaserad lösning det enklaste och mest praktiska alternativet för att utforska behoven inom projektet. Vi kan versions hantera en scen med git och använda AI verktyg för kodning för att skapa nya objekt och updatera egenskaper och information.
Datakatalogen kan naturligtvis ses som en till av många dataset som integreras i vår adressrymd. Skillnaden är dock att i de allra flesta fall är dessa dataset endast läsbara. Med datakatalogen så kan vi med andra ord också skriva och ändra datat.
Servers övergripande struktur
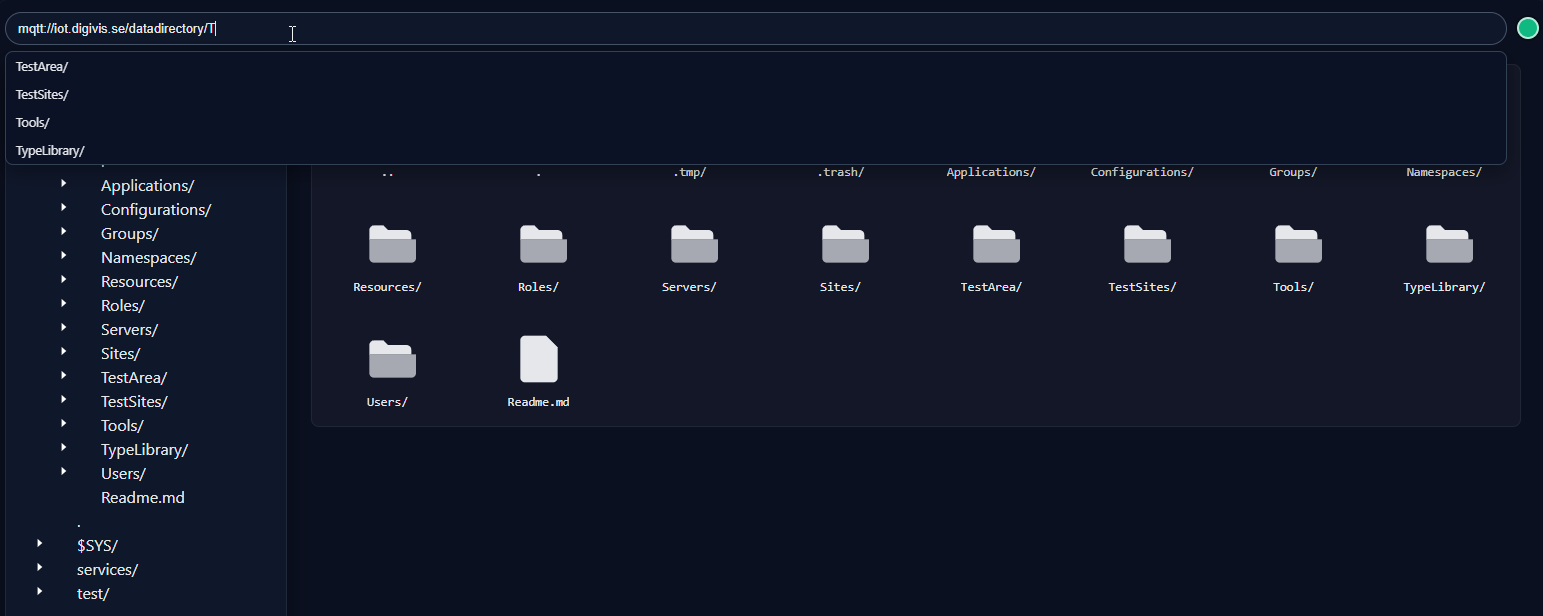
När man öppnar datadirectory så möts man av följande struktur:
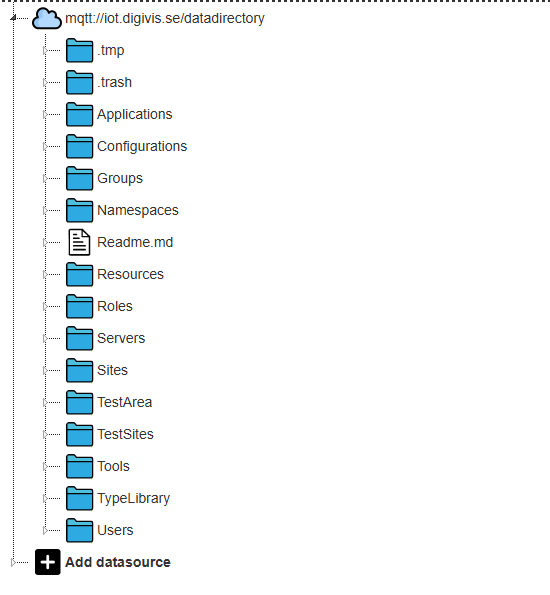
Under configurations så sparas configuring till vissa skript. Under Groups finns objekt som definierar de olika samarbetsgrupper som finns på servern. Under Users finns alla användare som finns upplagda på servern. Under Namespaces finns publik data.
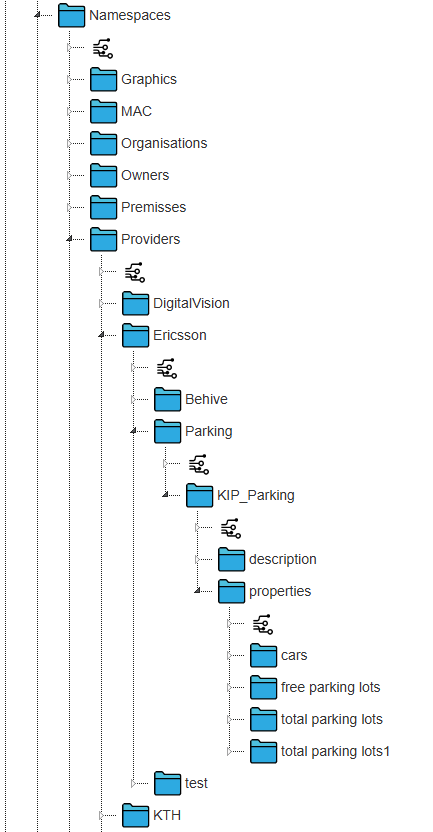
Under Namespaces är data indelat på ett sånt sätt att de får unika namn. I providers kanalen finns tex underkanaler för Ericsson och KTH där Ericssons sensor data och KTHs trafiksimuleringar strömmas in.

Går vi ner i grupp kanalen så ser vi att gruppen Digital Vision Kista finns representerad. Det finns en underkanal som listar scenerna i gruppen. Kista är utomhus vyn och Plan 6 är en inomhus vy i Electrum bygganden. Under users så ser vi även vila som är med i gruppen. Mappen innehåller länkar som i sin tur pekar på kanaler som ligger i Users katalogen som var med i den första bilden högre upp. Öppnar vi någon av scenerna så hittar vi därunder lagren som scenen innehåller under lagren objekten under objekten egenskaperna osv. Alla dessa är dock i sig själv objekt.
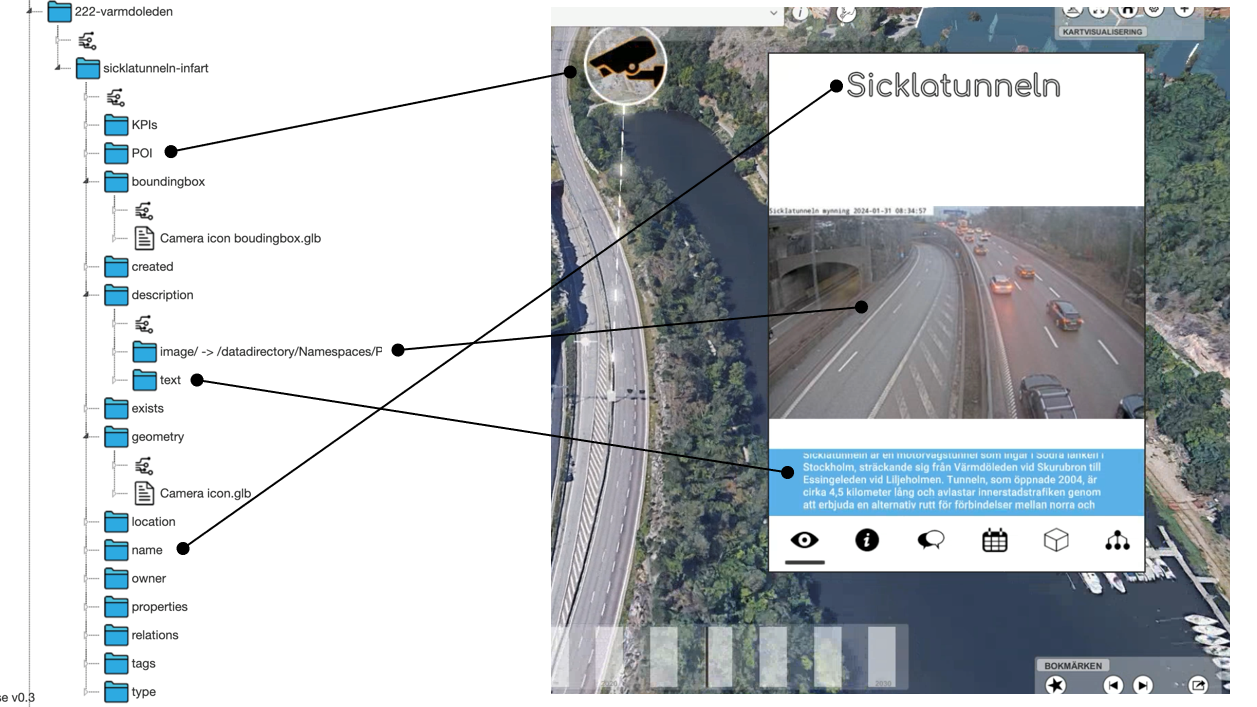
Definiering av ett objekt
Ett objekt i den digitala tvillingen definieras på följande vis:
I exemplet så ser vi en av Ericssons parkeringar i Kista Hårddisken. De två viktigaste egenskaperna är namn som lagras i kanalen name och type.
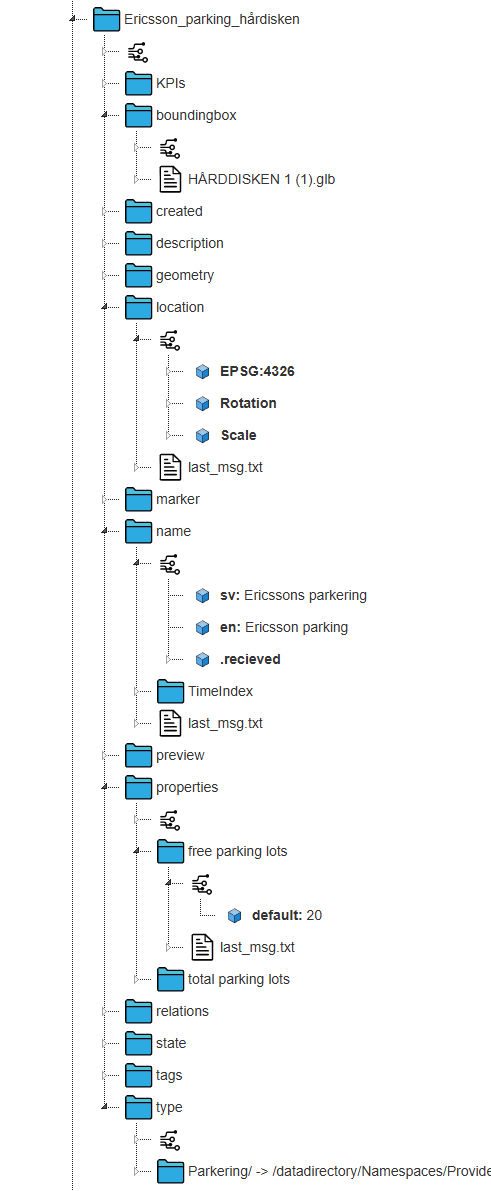
Expanderar vi name så ser vi att meddelandet i den kanalen innehåller namnet både på svenska och engelska. Vi kan naturligtvis lägga till fler språk om vi önskar. Typen på objektet är Parkering men typ kanalen innehåller en länk till en annan kanal där själva objektet Parkering definieras. Det finns också en description kanal med två underkanaler text och image. I dessa finns en text som beskriver objektet samt en eventuell bild.
Visualiserings styrning
Vissa kanaler styr visualiseringen av objektet i tvillingen. Tex:
- location innehåller koordinaterna för objektet om den har en fysisk plats. Den anger ofta centrumpunkten för objektet.
- marker ger en liten diamatformad symbol som visar centrumpunkten på objektet i tvilligen.
- boundingbox innehåller en 3D fil som visualiserar objektet gränser i 3D vyn. Dvs ritar in dem på marken och gör att man kan klicka på den delen av marken för att få upp informationen om objektet.
- geometry är också ett 3D objekt men används när objektet inte redan finns i 3D kartan. Tex om det är en framtida hus.
- POI (point of interest) finns denna kanal som skapas en icon med en linje ner mot objektet. Om man lägger in en underkanal till denna med en bild så kommer iconen att utgöras av bilden i fråga.
- Preview ger en text och inte info när man för pilen över objektet.
- Offscreen indicator ger en bil i hörnen på bilden som alltid pekar mot objektet. Klickar man på pilen flyger kameran till objektet.

Skalbarhet och typer
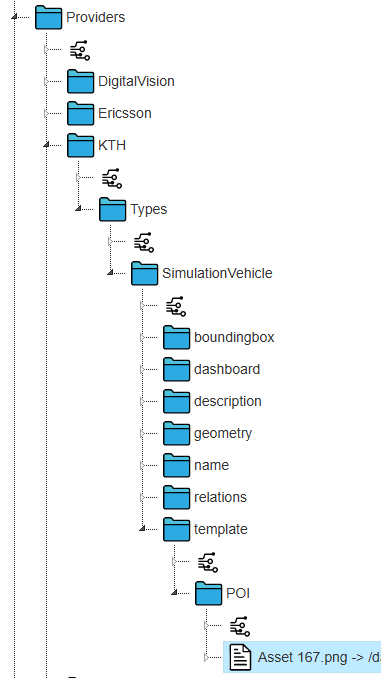
Skapar vi en mqtt://server2/personer/per/type så kan vi där länka till ett typ objekt. Typobjektet definierar vad objektet per är för typ. Tex person, parkering eller TA-plan (trafikavstängingsplan) som i exemplet ovan. Det innehåller som alla andra objekt namn och beskrivning på flera språk och iconer och bilder.
Det finns även en kanal under type objektet som heter template. Alla saker som placeras i template kommer att kopieras över objekten som är definierad att vara av den aktuella typen. På så sätt så behöver vi inte skapa en POI för varje objekt av en viss typ utan kan bara lägga en POI i template kanalen för dess typobjekt. För KTHs simulering av fordon där det finns 1000tals objekt så vore det opraktiskt att ladda upp en icon i POI kanalen för vart ett av dessa. Nu kan vi istället bara definiera typen SimulationVehicle och där efter skapa i den kanalen skapa template/POI och lägga den icon som alla simulerade bilar ska ha där.
Samarbets- och chat- funktioner
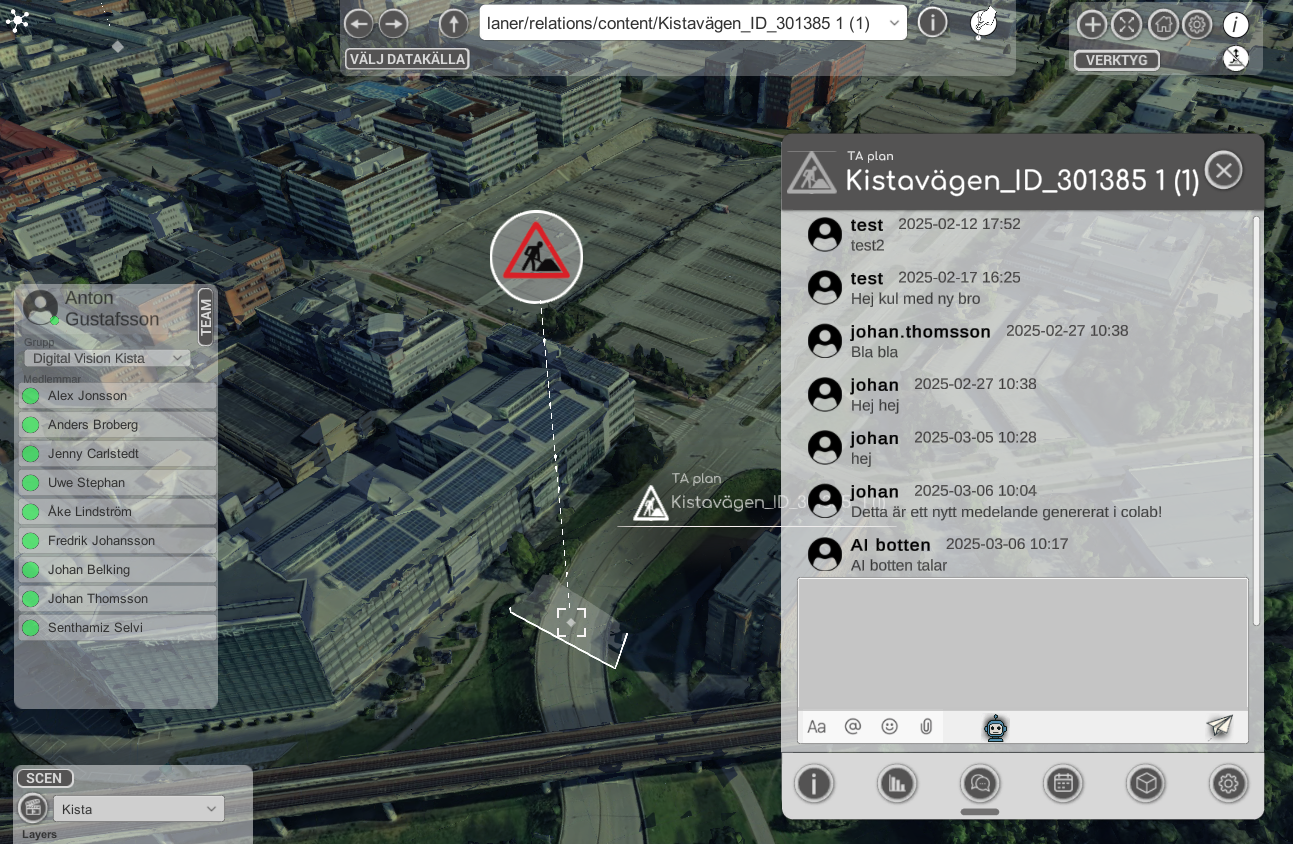
Som en sista del i projektet så började vi också att utforska hur vi med olika chatbottar kan förstå datat i den digitala tvillingen. MQTT är ett realtidssytem med kanaler och passar därför ypperligt för att skapa chatfunktioner eller sammarbetsfunktioner där en användare kan ändra någonting och övriga användare direkt ser förändringen. Detta ger möjligheter att skapa en samerbetsplattform där vi likt verktyg som Mural kan se andras digitala positioner eller likt google docs kan skriva på samma tex i realtid.
När det gäller just chattfunktionerna på de olika objekten så kan vi ju inte bara lägga till en kanal direkt under varje objekt där man diskuterar det aktuella objektet då det objektet kan vara del av flera olika gruppers scener. Lösningen blev att skapa ett nytt prefix dvs vi om vi chattar om ta planen nedan som ligger på tex mqtt://iot.digivis.se/datadirectory/Namespaces/Providers/trafiken.nu/TA-planer/Kistavägen_ID_301385
Så lägger vi till ett prefix för gruppen som gör att chatten endast kan ses mellan gruppmedlemmar: mqtt://iot.digivis.se/datadirectory/Groups/Digital Vision Kista/channels/
Chattmeddelandena hamnar då på adressen: mqtt://iot.digivis.se/datadirectory/Groups/Digital Vision Kista/channels/iot.digivis.se/datadirectory/Namespaces/Providers/trafiken.nu/TA-planer/Kistavägen_ID_301385
Ett exempel på AI integration
Följande scenario visar hur vi använder den femdimentionella realtidskunskapsgrafen för att interagera med data med hjälp av chatgpt.
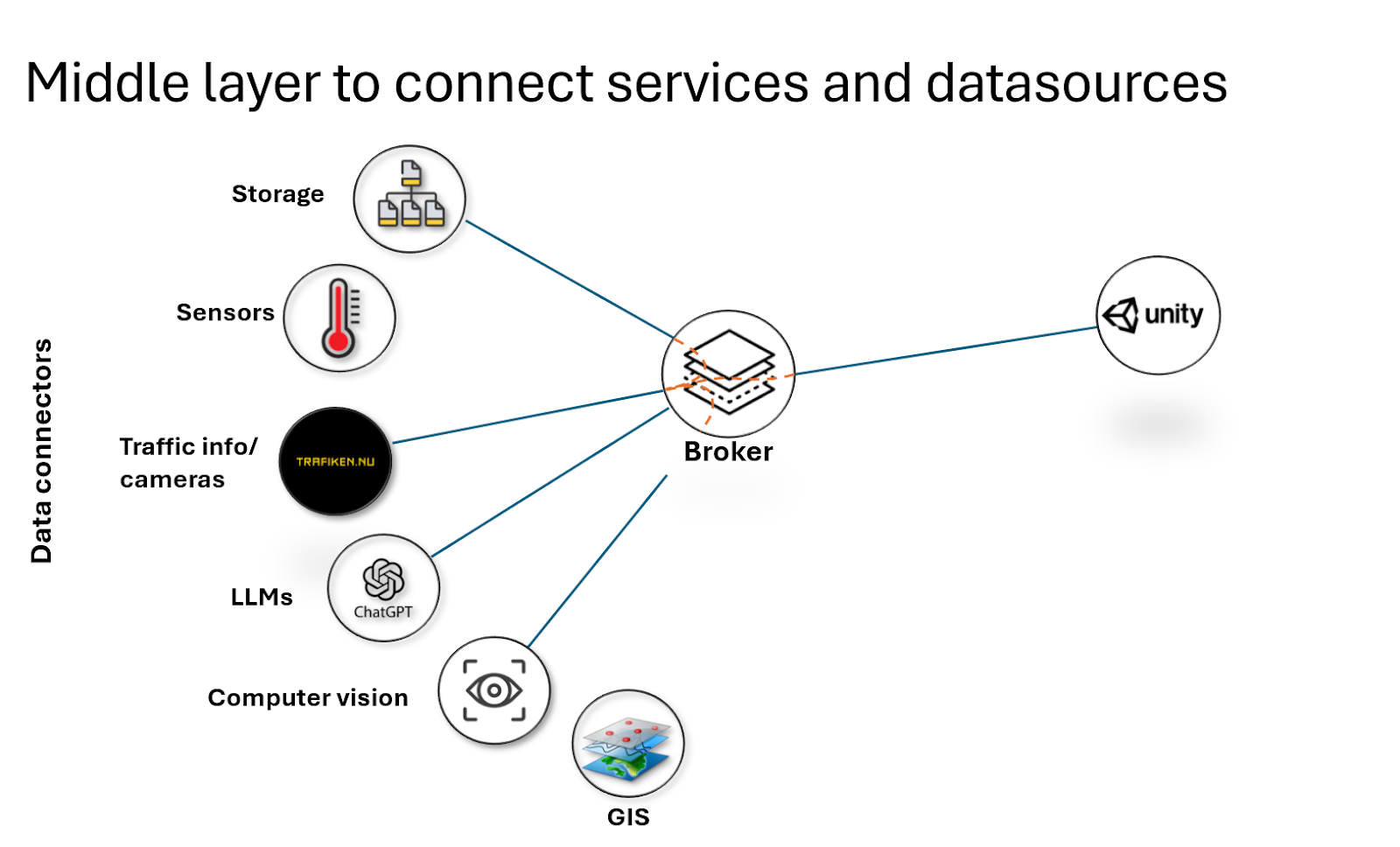
- En klient (Unity i bilden) ansluter till brokern och begär bland annat ut kamerabilder från en trafikkamera. Brokern ansluter upprättar en prenumeration som gör att alla nya bilder vidarebefordras till klienten. Sedan tidigare finns en koppling mellan en lagringstjänst (Storage) och kameraflödet som gör att klienten också kommer åt historiska bilder.
- En algoritm för datorseende prenumererar på samma kamera feed. När nya bilder anländer så räknar den bilarna i bilden och publicerar det i en annan feed på brokern. Lagringstjänster prenumererar på denna och lagrar antalet bilar historiskt.
- Användare skriver till chatbotten i chatfönstret för kameran. “Visa mig den tidpunkt i februari när det var som mest trafik".
- Meddelandet publiceras i en kanal som LLM skriptet prenumererar på. När skriptet tar emot meddelandet så skickas en förfrågan till en server där LLM en körs.
- LLM:en genererar ett kommando som skickas till LLM skriptet om att göra en slagning mot lagringstjänsten kring feeden med räknade bildar.
- LLM:en får tillbaka ett svar på vilken tidpunkt som är den som har mest bilar på den aktuella kameran.
- LLM:en formulerar ett svar som skickas till klienten. Svaret innehåller både ett svar till användaren i textformat men även ett kommando som körs på klienten och ändrar den till det aktuella datumet.
- Användaren kan nu läsa textmässigt vilket datum som är det med mest trafik och hur många bilar som identifierades under den aktuella tidpunkten. Användaren får också tiden spolat till den aktuella tidpunkten och kan med egna ögon se hur det såg ut i kameravyn då.
Att beskriva alla olika principer som vi utforskat kring hur en digital tvilling plattform för fungera är tyvärr bortom denna rapport. Men varje utforskat koncept har tagit oss närmare en förståelse för hur man bygger ett system som hjälper oss föra samman olika data och skapa en förståelse kring vad som händer i en stad. Vårt mål har här varit att på ett någolunda begripligt sätt beskriva vårat utforskande och resultatet av detta.
Om du tagit dig så här långt genom texten. Skriv gärna en kommentar i fältet nedan. Vad tyckte du? Finns det saker som kan förbättras? Vad skulle du vilja veta mer om?